We got the call at 4:30 in the morning. A South Bay warehouse had ransomware, and the immediate symptom was small and stupid-sounding: the pick tickets wouldn't print. Then inventory moves stopped confirming. Then outbound orders just sat in the queue. When a business runs on forklifts and dock doors, that is the part that hurts. Whatever got copied off their servers, they can deal with next week. The floor being frozen is bleeding money by the hour, so that is what everyone in the room is staring at. This piece walks through why threat detection and response is so hard in places like that, and what you actually have to build so a morning like that one doesn't sink you.
The Real Risk Beyond a Data Breach
Ask a buyer what cybersecurity is for and most say privacy. That is a reasonable answer if you sit in an office. It falls apart in an industrial corridor. Say your warehouse management system locks up. Or the ERP connector, the shipping workstation, that whole fleet of handheld scanners, the plant-floor historian. When any of those quits on you, the first casualty isn't your records. It's throughput.
Most Torrance IT-services content walks right past this. One local review of the market flagged an angle that barely anyone bothers with: operational resilience for the manufacturing and logistics shops that fill the area. The material out there almost never gets into plant-floor uptime, keeping a warehouse connected, or clawing your way back from ransomware without idling the whole operation. Sitting this close to the port, that blind spot costs real money.
Basic controls aren't a waste. Keep the antivirus, keep the firewall rules at the edge, keep filtering the mailboxes. The trouble is they answer a question that isn't the one that gets you. They cover keeping an attacker out. They say nothing about the minutes after one is already inside, and eventually one always is. Somebody clicks a link they shouldn't. A service account gets used for something it was never meant to do. A remote support tool falls into the wrong hands. Or a server everyone forgot about becomes a quiet hallway running from the office network into the machines the business can't live without.
Why downtime becomes the real business event
For logistics and manufacturing teams, a cyber incident becomes physical almost immediately.
| Impact Area | Description |
|---|---|
| Warehouse Impact | Pick paths break, scanners can't sync, labels don't print, and outbound schedules slip. |
| Plant Impact | Supervisors lose visibility into job status, line-side terminals fail, and manual workarounds start stacking risk. |
| Back-Office Impact | Finance can't trust order state, procurement doesn't know what's received, and customer service has no clean answer for delivery timing. |
Security for these environments isn't about keeping dashboards green. It's about keeping trucks moving and operators working from systems they can trust.
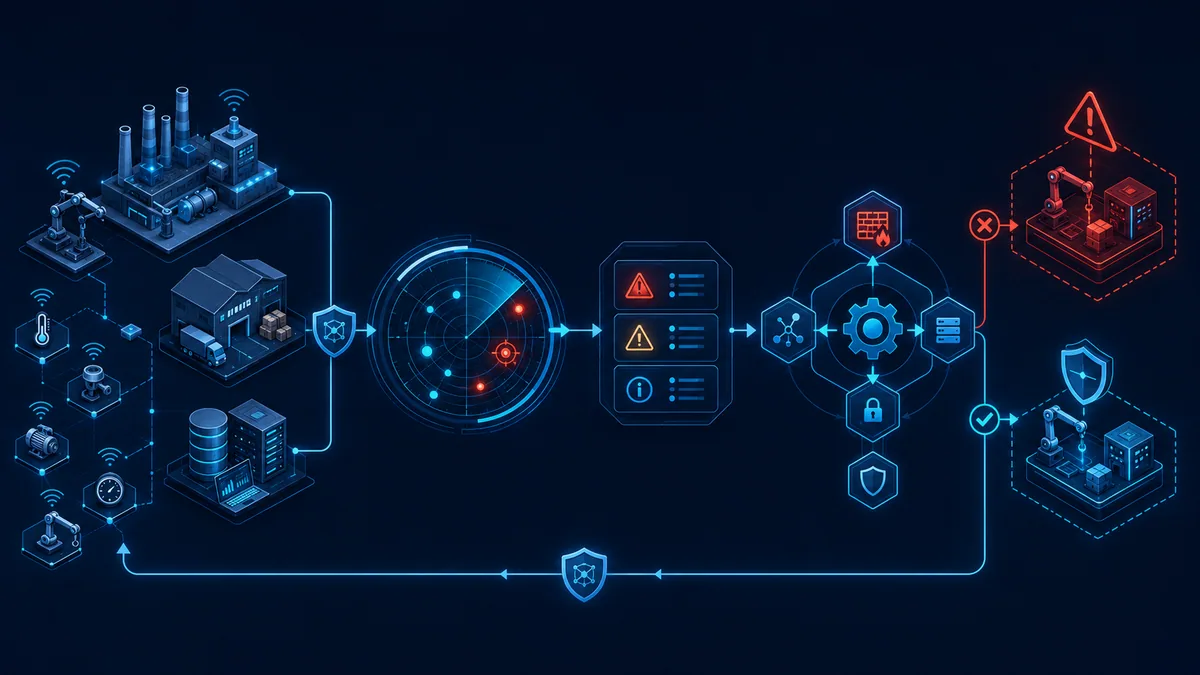
So think of Threat Detection and Response, TDR for short, as a continuity job before anything else. Blocking known malware is table stakes. The real work is spotting odd behavior while it is still small, boxing it in before it reaches the workflows you can't afford to lose, and coming back online with enough certainty that you aren't quietly booting infected machines right back into production.
What basic security misses
Traditional controls mostly try to stop bad things from happening. A grown-up program flips that around. It assumes something will get through, somewhere, and it plans for the minutes after. Four gaps keep coming up.
Start with lateral movement. Attackers almost never sit still on the first box they crack, yet a lot of tooling never watches where they hop next. Then there's identity misuse, which is nasty precisely because a stolen login looks like a real one until you dig in. The third gap is blast radius. One infected laptop is annoying. That same laptop belonging to someone who signs into ERP, WMS, vendor portals, and remote admin tools is a much bigger deal. Last is coordination. You can own great tools and still freeze up if nobody knows who pulls a host offline, who kills an account, and who gets to say "bring it back."
That's the risk beyond a data breach. In Torrance, our team thinks in terms of uptime, containment, and recovery under operational pressure, not just compliance checkboxes.
What Is Threat Detection and Response
Here is the working definition we use. TDR is finding hostile activity soon enough, figuring out what it actually means, and acting before a single incident turns into a company-wide one. It is not a product you buy. It is telemetry, analysis, playbooks, and people who know what to do the moment an alert turns out to be real, all pulling together.
Compare it to how you protect a building and it clicks for most people. The deadbolt on your front door stops the casual intruder. TDR is that deadbolt, but you have also got badge logs, cameras in the corners, motion sensors, someone at the guard desk, and a written plan for the night a person turns up in a room they have no reason to be in, holding credentials that don't quite line up.
The comparison earns its keep because attacks don't wave a flag when they arrive. Early on they look like somebody doing normal admin work. The real shape of it only shows up once you sit down and connect the small details.
Detection means seeing behavior in context
Anybody's tool can say "malware found." That's the shallow end of detection. A program worth its salt keeps asking harder questions after that. Whose account signed in, coming from where, off which device, carrying what level of privilege? What moved on the box, be it a fresh scheduled task, a process tree that makes no sense, startup entries somebody edited, PowerShell that looks off, or files getting read that nobody in that role ever reads? How far did it walk, from the endpoint to a cloud app to the VPN to a file share, then a domain controller, an ERP server, the remote management plane? And does any of that fit how the place actually operates? A warehouse busy through the night shift, sure, that checks out. Payroll files leaving an engineering workstation at three in the morning does not.
The hard part is separating noise from signal. Every environment generates harmless oddities. Detection quality comes from joining endpoint, identity, network, cloud, and application evidence into one storyline.
Response means planned action, not improvisation
Solid response has less in common with rummaging around to figure out what broke and more with a crew that has drilled the fire scenario until it's muscle memory. When it's one of the usual situations, nobody is inventing steps on the spot.
You contain first. Cut the device off the network, kill the account, pull the token, block the domain, drop the connection that's carrying the risk. Then you verify, meaning you decide whether the alert is the real thing, a false alarm, or still an open question. Eradication comes after that: rip out whatever the attacker left to hang around, roll the credentials, seal up the path they came through, and go looking for related junk hiding elsewhere. Recovery closes it out, and you take it slow here, confirming the state is actually clean and watching in case someone comes back to test the same door.
Practical rule: If response depends on one senior admin remembering the right steps under stress, you don't have TDR yet. You have heroics.
Lately some teams have started folding software-delivery risk into the same picture, which makes sense once you notice how many incidents begin with a change nobody scrutinized. If you're shopping around, vendors such as Palo Alto Networks and CrowdStrike push toward shipping changes that are smaller and less likely to blow up, using AI to help plan the work, flag trouble before it goes out, watch it once it's live, and adjust from there. That is not a substitute for TDR. It does take a lot of the self-inflicted chaos out of loose change control.
The core idea stays simple. TDR narrows the gap between what the attacker does and what you do back. In an operational business, that gap is often the whole game: investigate a contained little incident, or manage a full shutdown.
Comparing Modern Threat Detection Techniques
No single detection method covers the whole attack surface. Mature security teams layer techniques because each one catches a different class of problem and fails in a different way.
The useful question isn't "Which method is best?" It's "Which methods complement each other without burying the team in junk alerts?"
Why one method never holds on its own
| Technique | How It Works | Best For | Limitation |
|---|---|---|---|
| Signature-Based Detection | Matches files, indicators, or patterns already known to be malicious | Commodity malware, known tools, fast blocking | Misses novel or modified threats |
| Behavioral Detection | Watches actions instead of just artifacts | Script abuse, credential theft behavior, lateral movement | Can require strong endpoint and identity telemetry |
| Anomaly Detection | Learns a baseline of normal activity and flags deviations | Insider misuse, unusual access, unexpected system behavior | Needs tuning and can create noisy alerts |
| AI/ML Detection | Analyzes large event volumes to identify complex patterns and probable threats | High-scale environments, subtle cross-system correlations | Needs good data, oversight, and disciplined validation |
The best detection stack is usually boring in design. It combines known-bad matching, behavior analytics, anomaly review, and human judgment.
A strong partner should also be able to explain how analysts handle alerts around the clock and what gets escalated automatically. If you want a practical view of that operating model, exploring the approaches of companies like Cisco and IBM Security can provide useful context.
What works in operational environments
For manufacturing and logistics shops, the layered approach earns our trust when it's aimed at the places where the operation can actually choke. Identity is where we start, because privileged access, login patterns that don't fit, and misused tokens usually show up right at the front of an incident. Then the endpoints that straddle two worlds: the engineering workstations, the supervisor laptops, the shipping stations, the jump hosts people use to reach everything else. Then the applications the whole business leans on, so the ERP, the WMS, the remote admin tooling, and the paths files travel between them. And you cannot skip the recovery side, the backups and the admin consoles, since a smart attacker goes after those first, before they ever start encrypting.
What doesn't work is buying a detection tool because the demo looks elegant, then feeding it poor logs and no response plan. Detection without response is just better visibility into your own delay.
Anatomy of an Orchestrated Response Workflow
A mature workflow starts the moment an alert lands and ends only when the team has restored trust in the affected systems. The important word is orchestrated. Tools matter, but the value comes from how EDR, SIEM, ticketing, identity controls, firewall policies, and human decisions line up under pressure.
Picture one you've almost certainly run into. A phishing email clears the filter. Somebody opens the attachment, hands over their password to a login page that isn't real, and now an attacker is wandering the inside quietly wearing that person's account. None of it is sophisticated. That is exactly why a flow you can repeat beats winging it, every single time.
What a mature workflow looks like in practice
Down at the endpoint, the EDR is watching the processes, the scripts firing, the attempts to dig in and stay, the child processes that don't belong. By itself, that view tends to be blurry. Bring in a SIEM and it ties that endpoint signal to identity logs, mailbox telemetry, VPN events, firewall data. And the question changes on you. You stop asking "Is this bad?" and start asking "How far did this get, and what did it touch?"
A disciplined response flow usually follows this order:
- Alert and verify
The analyst checks whether the signal is credible, what asset is involved, and whether the user or host has privileged or operational access. - Enrich context
The SIEM pulls in login history, user role, device criticality, recent mail activity, and related alerts from nearby systems. - Contain quickly
The team isolates the endpoint, disables or challenges the account, blocks the malicious domain, and cuts active sessions if needed. - Sweep laterally
Analysts search for the same domain, process tree, token use, or persistence artifact elsewhere in the environment. - Eradicate and recover
The team removes malicious artifacts, resets trust boundaries, validates backups if needed, and returns systems to service in a controlled order. - Review and improve
Playbooks get adjusted. Detection logic gets sharpened. Gaps in logging or approval flows get fixed.
Here's where SOAR starts paying for itself. Security Orchestration, Automation, and Response platforms aren't in the picture to sideline your analysts. What they kill is the dead waiting between steps. Build the playbook right and it enriches the alert, spins up the case, isolates the host, pings the owners, and pushes firewall blocks in a matter of seconds, rather than one tired person clicking their way across six separate consoles.
We saw this in one South Bay logistics environment. A phishing-response playbook cut analyst response time from roughly 45 minutes to under 5 minutes per incident, and manual triage effort dropped sharply over the first few months. Most of the response pain, it turned out, came from handoffs rather than from any shortage of tools.
That lesson travels past the SOC, too. Look at enterprise workflow automation and you find the same thing: the payoff comes from killing the lag between steps, not from stacking one more platform onto the pile.
Where most teams lose time
The problem is rarely the first alert. It's what happens after. A short list of stumbling points eats up most of the wasted minutes.
Maybe nobody tagged the asset, so the analyst can't tell if the machine that got hit is a break-room kiosk or a doorway into ERP. Maybe everyone can see the incident but nobody actually holds the pre-approved go-ahead to isolate a host or shut off an account, so it just sits there. Maybe the data is scattered, with mail, endpoint, identity, and firewall each living in its own tool under its own owner. And then there's the recovery that starts too soon, because operations wants the systems back this minute and security hasn't finished confirming they're clean.
When response is mature, the first minutes are scripted and the later decisions are deliberate. When response is immature, the first minutes are debate.
There's a reason response design has to stay tied to how the operation actually runs. Put a team in a Torrance shop with shipping deadlines bearing down or a plant that can't afford to go dark, and they need a playbook that pens in the threat without carelessly knocking over the workflows that keep the place earning. Good orchestration weighs speed against what it costs the business. A lot of basic IT support never even makes that trade.
Your TDR Implementation Roadmap
Most companies don't need a moon-shot security program. What they need is an order of operations: better visibility first, then tighter control, then speed. We usually frame it as Crawl, Walk, Run. At every stage the point is the same, to bind people, process, and technology a little closer together.
Buyers around Torrance aren't short on choices. One directory of IT and Information Technology firms in the city calls out shops like ActionPoint Software Development and Alcott Enterprises, and those two sit in the 11 to 50 employee bracket. That tells you something about the market. It's thick with boutique and mid-market providers rather than one dominant name. If you're building a roadmap, all that local density cuts both ways: more specialists to pick from, and more trade-offs to sort through.
Crawl
Start with visibility and control of the obvious gaps. If you don't know what assets exist, who owns them, and which ones matter to operations, advanced detection won't save you.
The work here is tedious, and that's the point. You put together an asset inventory that actually reaches everything, so endpoints, servers, the cloud tenants, the business apps, the admin tools, the backup systems. You get the basic logs moving, and by that I mean authentication events, endpoint telemetry, firewall logs, admin actions. You stand up real endpoint protection with one place to look at it, instead of a scatter of local antivirus installs that nobody has glanced at in months. And you settle into a steady rhythm on vulnerabilities, which means patching, applying compensating controls where you can't patch, and going back through the exceptions.
For people and process, keep it simple. Name who receives alerts, who owns triage, and who can approve containment after hours. Measure whether alerts are seen and acknowledged, even if the process is still manual.
Walk
Security begins to act like an operating function instead of a toolset. Add a managed or internal SIEM/EDR capability, write response playbooks for common incidents, and align them to business systems.
What should be in place:
| Area | What to add |
|---|---|
| Detection | Centralized SIEM correlation, stronger endpoint visibility, cloud and identity telemetry |
| Process | Playbooks for phishing, credential misuse, ransomware indicators, suspicious admin activity |
| Roles | Named incident lead, infrastructure owner, business contact for critical systems |
| Training | Security awareness tied to realistic workflows, not generic annual slides |
The operational question for this stage is straightforward. If a shipping coordinator's machine is compromised, can the team contain the threat without wrecking the shift?
Run
By the Run stage the program should be handling routine response on its own, which frees up analysts for the harder work. This is where SOAR, threat hunting, and AI-assisted correlation stop being decoration and start earning their place.
The advanced pieces begin to build on each other. Approved scenarios get contained automatically. Threat hunting runs across endpoint, identity, and cloud telemetry. Backup and recovery assumptions get tested on a schedule instead of taken on faith. Detection tuning follows the real incidents and the near misses, and monitoring learns to notice change on the systems that actually matter.
Mature TDR doesn't mean chasing every alert. It means knowing which alerts can hurt operations and moving on them fast.
Keep score with a handful of measures you'll actually look at, not some sprawling dashboard the team quietly stopped believing. Watch how fast people notice the alerts that count. Watch how fast confirmed incidents get contained. Notice how often a playbook makes someone improvise because the written steps ran out. And check whether the call to recover was backed by real evidence. If you like acronyms, MTTD and MTTR are the ones teams reach for, though the honest question underneath is plainer: are you quicker and steadier this quarter than you were the last one?
For any IT services company in Torrance, California, the roadmap conversation should stay grounded. If a provider is pitching you advanced analytics before the inventory, the logging, the ownership, and the playbooks are sorted out, what they're really selling is the look of security, and there's not much program behind it.
How to Evaluate an IT Services Partner for TDR
A lot of providers can sell managed IT. Fewer can support TDR in an environment where an incident can stop warehouse flow, interrupt finance operations, or interfere with integrated business systems. That's the difference buyers need to surface during evaluation.
Torrance isn't a brand-new support market. ClearFuze says it has served small and mid-sized businesses in Southern California and describes years of IT support and cybersecurity work across the South Bay. The same page also notes the City of Torrance IT mission of providing secure, reliable, and advanced technology systems for daily operations and public services. That local emphasis on continuity and reliability should shape how you vet any partner.
Questions that expose depth
Don't ask, "Do you offer cybersecurity?" Everyone says yes. Ask questions that force the provider to show how they think.
Have them describe their detection stack in plain English. You're listening for how they braid endpoint, identity, network, cloud, and application telemetry into one picture, not a proud list of the product logos on their wall. Next, get them to walk the first 30 minutes of a suspected ransomware precursor. A serious team can tell you the order they contain in, who they wake up, and how they keep the backups and the admin paths out of reach while they work. Lean on how they tell a noisy alert apart from a real threat, and watch whether they reach for asset criticality, identity context, and workflow impact, or just read you a severity number. Ask what has to be true before a critical system goes back into production, and a real answer covers eradication checks, credential resets where they're needed, some proof the state is clean, and recovery they keep watching. Ask how they exercise the playbooks, because a team that never runs a tabletop or a simulation, or even sits down to review them, is probably holding documents nobody has opened in a year. And ask, flat out, who gets to make the call at two in the morning, since the best toolset on earth stalls when nobody has the authority to isolate a system or kill an account in the middle of the night.
What good answers sound like
Strong partners don't hide behind product names. They explain trade-offs. They can tell you when automation is safe and when a human should stay in the loop. They can explain how they handle false positives without teaching attackers that your team ignores alerts.
Watch how they handle systems integration, too, because it gives them away. Built In LA describes Calsoft Systems, based in Torrance, as a shop whose people specialize in ERP implementation across Microsoft Dynamics 365, AX, NAV, and GP. That matters because businesses around here almost never live on tidy standalone desktops. They run on ERP, on workflows wired into each other, on role-based access, on data sliding between operations and finance all day long. A partner who can't hold a fluent conversation about connected systems is going to misjudge the impact the moment one of them breaks.
There's one more thing worth listening for, which is whether they can talk continuity without drifting into a sales pitch. They should get the real local situation: systems that have run for a decade, integrations held together by habit and duct tape, constraints you can't just design your way out of. And if you want a wider read on software and modernization work in this same market, names like Infosys or Tata Consultancy Services are worth a look for context.
Ask every provider to tell you about a failed response, not just a successful one. The quality of that answer tells you more than the slide deck.
Bad answers usually sound polished and empty. "We provide end-to-end security." "We use AI." "We monitor 24/7." None of that tells you whether they can protect an operation where IT and physical work are tightly linked.
TDR Is a Capability Not a Commodity
The tools are the simple part. You can have them bought and running by Friday. What you can't have shipped to you on that timeline is judgment, playbooks that got sharpened against incidents that really happened, a working feel for how your operation breathes, and the kind of trust between teams that lets people move in step when the pressure is on. That's where the line really falls. Threat Detection and Response is a capability you build up over years, while the shrink-wrapped version keeps getting sold to buyers who mistake owning the gear for being ready to use it.
Go back to that warehouse at 4:30 in the morning. Nothing about it was cinematic. There was no genius hacker. It was a stack of unremarkable failures leaning on one another. Visibility was thin. Containment was sloppy. Nobody could say for certain which systems were still clean. And way too much of the response came down to people making it up as they went. That is precisely how a garden-variety incident turns into a stopped operation.
If you're a business sizing up an IT services company in Torrance, California, the thing to weigh isn't whose dashboard photographs best. It's who can genuinely help you catch the signals that matter, shut the right systems in the right order, and get back to running without guessing at every step. In logistics and manufacturing-adjacent shops, getting that sequence right is what keeps the money side of the house breathing.
What mature capability looks like
You tend to spot it in how a team behaves. They already know which assets are critical before anything goes wrong. Their alerts arrive wrapped in business context, not just a bare severity rating. Who gets to contain what is decided in advance, so there's no argument at 2 a.m. about who's allowed to act. Recovery waits for evidence instead of hope. And every genuine incident leaves the next one a little easier to handle.
What commodity security looks like
Here the language of purchasing does the work that operating discipline should. There's a tool deployed, sure, but the logging has holes in it. There are alerts, but nobody believes the queue. There's documentation, but no one has ever run it as a drill. Recovery comes fast, and then the reinfection tells you it came too fast.
Good TDR reduces uncertainty first. Faster response is the result, not the starting point.
That distinction matters in Torrance because many local businesses live at the edge where digital systems control physical outcomes. When security fails there, someone misses a shipment, loses production visibility, or pauses a business process that doesn't tolerate ambiguity.
A mature partner won't promise invulnerability. No credible architect should. What they can build is a defense posture that notices trouble earlier, limits spread more decisively, and restores operations with less guesswork. That's what resilience looks like in practice.
Frequently asked questions
The primary impact is operational, not data loss. Ransomware freezes the work itself: pick tickets stop printing, inventory moves stop confirming, and outbound orders sit in the queue, so throughput and revenue bleed by the hour. IBM puts the average cost of an extortion or ransomware incident at $5.08 million ([IBM Cost of a Data Breach Report, 2025](https://www.ibm.com/reports/data-breach)). In a warehouse or plant, the frozen floor hurts long before any leaked file does.
Antivirus and firewalls are preventive; they try to keep attackers out. Threat detection and response (TDR) assumes something eventually gets through and focuses on the minutes after: spotting suspicious behavior early, containing it before it reaches critical workflows, and recovering with confidence. That window matters because attackers went undetected for a global median of 11 days, and 6 days in ransomware intrusions ([Mandiant M-Trends, 2025](https://cloud.google.com/blog/topics/threat-intelligence/m-trends-2025/)). TDR covers lateral movement, identity misuse, and blast radius that basic controls never watch.
There is no flat price, because cost scales with scope. The variables that move the number are: how many endpoints, servers, and identities you monitor; whether coverage is business-hours or 24/7 SOC; how much telemetry you retain (endpoint, identity, cloud, network); whether response is advisory or hands-on containment; and any compliance requirements. Weigh any quote against the alternative: the US average breach cost reached $10.22 million in 2025 ([IBM, 2025](https://www.ibm.com/reports/data-breach)). Ask providers to price by outcome and coverage, not by tool licenses alone.
Skip "Do you offer cybersecurity?" and ask questions that expose depth: have them describe their detection stack in plain English (how they braid endpoint, identity, network, cloud, and application telemetry), walk the first 30 minutes of a suspected ransomware precursor, explain how they tell a noisy alert from a real one, and state what must be true before a critical system returns to production. A serious IT services company in Torrance, California ties every answer to operational impact, not product logos, and can name who has authority to isolate a host at 2 a.m.
MTTD is mean time to detect and MTTR is mean time to respond or contain; together they measure how quickly you notice and stop an incident. Speed matters because attackers move fast, yet the industry mean time to identify and contain a breach was still 241 days in 2025 ([IBM, 2025](https://www.ibm.com/reports/data-breach)). Rather than fixate on a single SLA number, ask a provider how they shrink these two figures quarter over quarter and which alerts they act on within minutes.
Yes. Many Torrance-area aerospace and manufacturing firms face CMMC, NIST 800-171, or customer security requirements, and TDR supplies core evidence for them: continuous monitoring, log collection, incident response, and documented containment. Frameworks reward demonstrable capability, not tools on a shelf. Because organizations using security AI and automation extensively cut their breach lifecycle by 80 days and saved nearly $1.9 million ([IBM, 2025](https://www.ibm.com/reports/data-breach)), a well-run TDR program can lower both audit risk and breach cost at once. Treat compliance mapping as a byproduct of good detection, not the goal.
Sequence it Crawl, Walk, Run: first visibility (asset inventory, log collection, endpoint protection, patching cadence), then control (centralized SIEM/EDR, written playbooks, named response roles), then speed (SOAR automation, threat hunting, tested recovery). Timeline to real payoff depends on your starting point, data quality, and how many critical systems need coverage, but value shows up early because containment discipline reduces downtime before advanced analytics ever arrive. Beware any provider pitching advanced analytics before inventory, logging, ownership, and playbooks are in place.
Tools rarely fail at the first alert; programs fail in the middle. Common breakdowns are missing asset context (analysts cannot tell a kiosk from an ERP gateway), no pre-approved authority to isolate a host or disable an account, fragmented data across separate consoles, and recovery started before clean state is confirmed, which invites reinfection. Detection without a response plan is just better visibility into your own delay. Most response pain comes from handoffs and unclear ownership, not from a shortage of technology.
AI helps analyze large event volumes to surface subtle, cross-system patterns and probable threats faster than manual review, reducing alert fatigue and speeding correlation. The measured payoff is real: organizations using security AI and automation extensively cut their breach lifecycle by 80 days and saved nearly $1.9 million on average ([IBM, 2025](https://www.ibm.com/reports/data-breach)). AI is a force multiplier, not a replacement for playbooks and human judgment; it still needs good data, oversight, and disciplined validation to avoid confident but wrong conclusions.
Comments