Your team is busy all day, yet core work still moves too slowly. Engineers spend too much time stitching together tools, managers chase status across disconnected systems, and every new initiative feels harder than it should. Revenue pressure rises, but capacity doesn't. That's the operational ceiling most CTOs are dealing with right now.
Operational efficiency improvement fixes that, but only when you treat it as a growth program, not a cleanup project. The point isn't to squeeze people harder. The point is to remove drag so your best teams can ship faster, resolve issues sooner, and spend more time on work that compounds. Companies that excel in operational improvement achieve 25% higher productivity and 20% lower operating costs than peers, according to McKinsey-referenced research summarized by 6Sigma. That's why this belongs on the CTO agenda.
A lot of leaders know this already. What they don't need is another generic checklist. They need a practical path to execution, especially if they want AI to do real work instead of becoming another half-adopted experiment.
Why Efficiency Is Your New Growth Engine
Most companies don't hit a growth wall because demand disappears. They hit it because operations can't absorb more complexity. Releases slow down. Support queues expand. Internal approvals multiply. The business keeps adding tools, vendors, and meetings, then wonders why output doesn't rise with spend.
That's why operational efficiency improvement should sit next to product strategy and platform strategy. If your delivery engine is clogged, growth becomes expensive. If your workflows are clean, growth gets cheaper and faster.
Efficiency creates capacity you can actually use
A mature CTO doesn't frame efficiency as “cut cost and move on.” That mindset is too small. The payoff is capacity. You free engineering time for product work. You reduce manual reporting. You shorten handoffs between teams. You stop paying senior people to do clerical coordination.
In strong organizations, efficiency creates room for three things:
- More shipping capacity: Teams spend less time on repetitive admin, status chasing, and rework.
- Better service performance: Issues move through the system with less friction and fewer avoidable delays.
- Faster strategic response: When priorities change, your operating model can adjust without weeks of cleanup.
Operational drag is a tax on growth. If you don't remove it, every new initiative costs more than it should.
AI matters here because it can absorb work that usually sits between systems and people. It can summarize tickets, route requests, extract data from documents, trigger downstream actions, and keep workflows moving without adding operational overhead. That's why many CTOs are looking beyond narrow scripts and into broader enterprise workflow automation programs.
Stop treating efficiency like a finance-only project
Finance tracks the impact. Operations and technology create it.
The organizations that move fastest don't wait for a company-wide transformation charter. They pick a workflow that's clearly painful, instrument it, and redesign it with automation and AI where it counts. They care about throughput, quality, responsiveness, and resource use. They don't treat efficiency as abstract management language.
A strong operational efficiency improvement program changes how work gets done day to day. That's what turns margin pressure into an execution advantage.
Establishing Your Baseline and Finding Bottlenecks
A CTO greenlights automation for a workflow that everyone complains about. Six weeks later, the team still misses SLAs, exception handling is worse, and no one trusts the new process. The problem was never the automation layer. The team never measured the actual workflow, so they automated delay, rework, and bad handoffs at scale.
Start with a baseline. No baseline, no improvement. You need a clear picture of how work moves today, where it stalls, who touches it, and what the delay costs.
Before you go deeper, use a visual map of the diagnostic path:
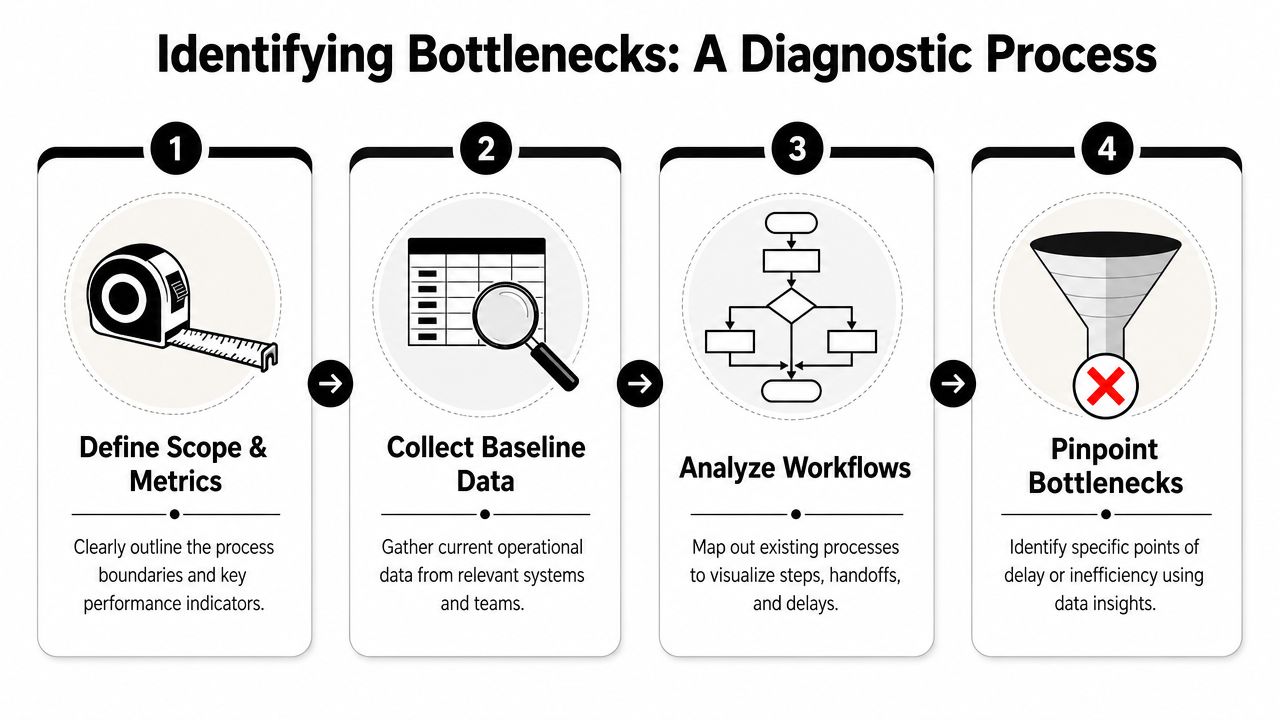
Start with one workflow that matters
Do not map the whole company. Pick one workflow with three traits. It affects revenue, service quality, or delivery speed. It runs often enough to generate usable data. It is painful enough that the business will support a fix.
Good candidates include software release approvals, customer onboarding, invoice processing, incident resolution, and lead handoff between marketing and sales.
Map the workflow exactly as it operates in production:
- Set the boundaries: Define the trigger that starts the process and the outcome that marks completion.
- Document every step: Include reviews, approvals, waits, tool switching, and rework loops.
- Assign actual owners: Record who performs each task, not just who owns the process on an org chart.
- Trace every handoff: Delays usually show up between teams, systems, or approval layers.
If you want an outside view before redesigning the workflow, an AI readiness assessment for automation and process redesign will show whether the problem needs AI, standard automation, or a simpler operating change. That matters if you want a hands-free implementation partner to fix the right constraint first instead of billing you to automate noise.
Measure the points of friction
Process maps expose flow. Metrics expose loss.
Use a small set of operational measures that reveal where work slows, breaks, or waits. Insightsoftware's operational efficiency analysis overview covers common measures such as cycle time, error rate, first-pass yield, utilization, and cost-related ratios. For a CTO, the goal is simpler. Track the few signals that identify the constraint and support a business case for change.
| Metric | What it tells you | Typical bottleneck signal |
|---|---|---|
| Cycle time | End-to-end duration | The workflow is too slow overall |
| Step time | Duration of each task | One activity consumes a disproportionate share of time |
| Error or rework rate | Quality failure points | Teams repeat work because inputs or decisions are wrong |
| Queue wait | Idle time between tasks | Approval layers or staffing gaps are holding work up |
| Resource utilization | Load on people or systems | Work piles up around a few overloaded roles |
Use several real process runs. One clean sample is useless. You need enough observations to separate a one-off exception from a repeatable operating problem.
A release workflow is a good example. Dashboards may show code moving on schedule, while the actual delay sits in security review, business sign-off, or manual packaging before deployment. Once you time each stage and each wait, the bottleneck is usually obvious. That is the point where a managed AI partner becomes valuable. They can instrument the workflow, confirm the root cause, and recommend the right intervention without pulling your internal team into a months-long diagnostic exercise.
This short walkthrough is useful if you want a quick operational lens before doing the deeper audit:
Separate skill gaps from system gaps
Leaders often blame tooling first. That is lazy diagnosis.
Some bottlenecks come from missing automation. Others come from inconsistent execution after a process change, poor intake discipline, unclear approval rules, or teams working from different definitions of done. If adoption is weak, your redesigned workflow will drift back to the old one and your projected ROI will disappear.
Use a simple rule. Do not approve automation until you can state the current bottleneck, the target metric, the process owner, and the adoption plan. If those four points are unclear, you are still in discovery.
That discipline is what makes operational efficiency a growth lever instead of another cost-cutting project. A strong baseline gives you something better than a process map. It gives you a defensible case for where AI should intervene, what the intervention should improve, and how a hands-free partner can prove the result.
Prioritizing Your Improvement Initiatives with AI
A CTO usually loses the quarter here. The team has a clean list of bottlenecks, five vendors are pitching automation, department heads all want their workflow fixed first, and the roadmap starts filling with disconnected projects. That is how efficiency programs turn into expensive activity with no measurable gain.
Set priorities like an investor, not a process committee. Fund the initiatives that free capacity, improve service speed, and create a clear path to ROI. Push everything else down the list.
Operational efficiency improvement comes from four levers: people, process, tools, and automation or AI. Every lever matters. They should not get the same budget or urgency.
Start with a clear model:
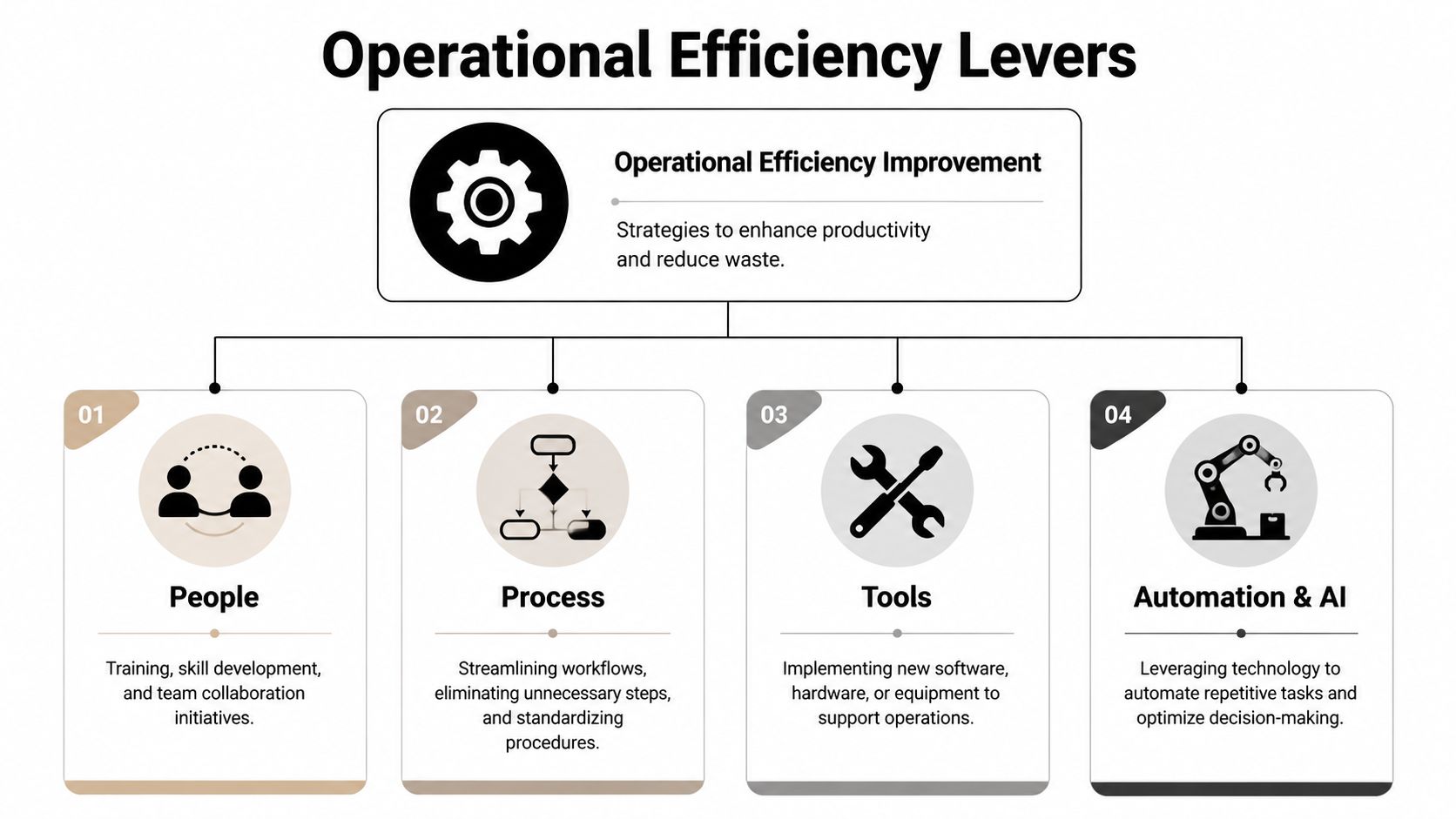
Use four levers, but fund the one that removes the constraint
Treat each lever as a different type of intervention.
- People
Prioritize this when the workflow is sound but execution is inconsistent. Fix role clarity, decision rights, training, and manager accountability before you spend on new systems. - Process
Prioritize this when the workflow itself creates waste. Extra approvals, unclear intake rules, duplicate reviews, and exception-heavy routing belong here. - Tools
Prioritize this when the process works but the stack slows it down. Re-keying data, switching between systems, and fragmented status views are tool problems. - Automation and AI
Prioritize this when teams spend time on repetitive judgment-light work. Triage, document extraction, policy lookup, exception flagging, and cross-system coordination are strong candidates.
The mistake is obvious. Companies buy AI to compensate for bad process design or poor operating discipline. That produces a demo, not an operating result.
AI deserves priority when the data and economics are clear
AI performs well when the work is frequent, the inputs are usable, and the value of faster execution is easy to prove. If your data sits across tickets, inboxes, spreadsheets, and line-of-business apps with no common structure, fix that first.
Microsoft's guidance on building a modern data estate makes the point clearly. AI outcomes depend on connected, governed data across the organization, not isolated systems and one-off exports (Microsoft on data estates and AI readiness). For a CTO, the implication is simple. Do enough integration and standardization to make the workflow legible before you scale automation into it.
This is also where a hands-free AI partner changes the economics. Your internal team should not spend a quarter evaluating ten use cases, estimating costs, mapping integrations, and debating architecture for every workflow. A managed AI transformation partner should do that work, rank opportunities by operational return, and bring you a short list tied to measurable outcomes.
Use AI first in workflows where the payoff is obvious:
- Ticket and request triage: Classify, enrich, and route incoming work without manual sorting.
- Document-heavy operations: Extract fields, validate records, and trigger downstream actions.
- Internal knowledge workflows: Retrieve the right policy or procedure fast and summarize it in context.
- Operational reporting: Compile updates, flag exceptions, and surface decisions that need human review.
If you need a disciplined way to compare implementation effort against business value, use a structured AI cost estimation framework for operational planning. It helps you reject attractive but weak use cases before they consume engineering time.
Do not ask where AI looks impressive. Ask where it removes recurring effort, protects quality, and increases throughput.
Apply a hard prioritization filter
Rank initiatives against business impact, delivery risk, and proof potential. If a project scores well on all three, move it up. If it fails one, challenge it. If it fails two, cut it.
| Question | If the answer is yes | Priority implication |
|---|---|---|
| Is the workflow repeated often? | The gain compounds over time | Move it up |
| Is the work rules-based or pattern-based? | Automation is feasible | Prioritize AI or workflow automation |
| Is the process stable enough to standardize? | The change is more likely to hold | Good candidate |
| Is the data accessible and consistent? | Measurement and control are possible | Safer to implement |
| Does the bottleneck consume scarce expert time? | Capacity gains are meaningful | Strong candidate |
Use this filter with discipline. A managed AI partner should score opportunities, pressure-test assumptions, and tell you where not to invest. That is the difference between a DIY efficiency program and an AI-led operating model that produces provable ROI.
Designing and Running a Successful Pilot Program
Big rollouts create political risk, technical risk, and adoption risk. A pilot cuts all three. It gives you proof, exposes failure modes early, and prevents you from industrializing a weak design.
Use a pilot to validate the operating model, not just the tool.

Pick a pilot with visible pain and limited blast radius
The best pilot area has three traits. The current process is painful. The workflow happens often enough to generate feedback quickly. The failure risk is manageable.
Good pilot candidates include internal service desk intake, customer onboarding document review, renewal workflow coordination, or a narrow release-management step. Avoid mission-critical processes with too many exceptions on the first round.
A smart pilot scope should answer these questions:
- Is the pain obvious? Teams should already agree the current way is inefficient.
- Can you measure it? If the baseline is fuzzy, the pilot result will be fuzzy too.
- Can you contain it? If something breaks, the organization should be able to recover fast.
Define success before you build
A pilot fails when the team starts with “let's test this tool” instead of “let's improve this outcome.” Define the business result first, then design the workflow, prompts, integrations, and controls around that result.
Use a compact scorecard:
- Primary metric: The single operational signal that matters most.
- Guardrail metric: A quality measure that prevents false wins.
- Owner: One person accountable for decision-making.
- Review cadence: Weekly is usually right for a live pilot.
- Exit condition: What has to be true to scale, revise, or stop.
If your team needs custom orchestration, integration, or model-enabled workflow logic, AI development services are often the difference between a demo and an operational system.
Treat the pilot like an operating rehearsal
Don't hide the messy parts. The point is to find them.
Run the pilot with real users, real exceptions, and real reporting. Capture where the workflow stalls, where humans override automation, and where data quality breaks the chain. You want enough signal to refine the process before scale.
A strong pilot review should include:
- Observed friction: Where users hesitate or bypass the system
- Exception handling: Which cases still need manual judgment
- Data reliability: Whether source systems support repeatable execution
- Change readiness: Whether managers are reinforcing the new behavior
The pilot isn't finished when the tech works. It's finished when the workflow works under normal operating conditions.
Scaling Success and Building Sustainable Governance
A successful pilot gives you evidence. It does not give you enterprise-wide durability. That takes rollout discipline, operating ownership, and governance that survives competing priorities.
Use a phased path instead of a hard cutover:
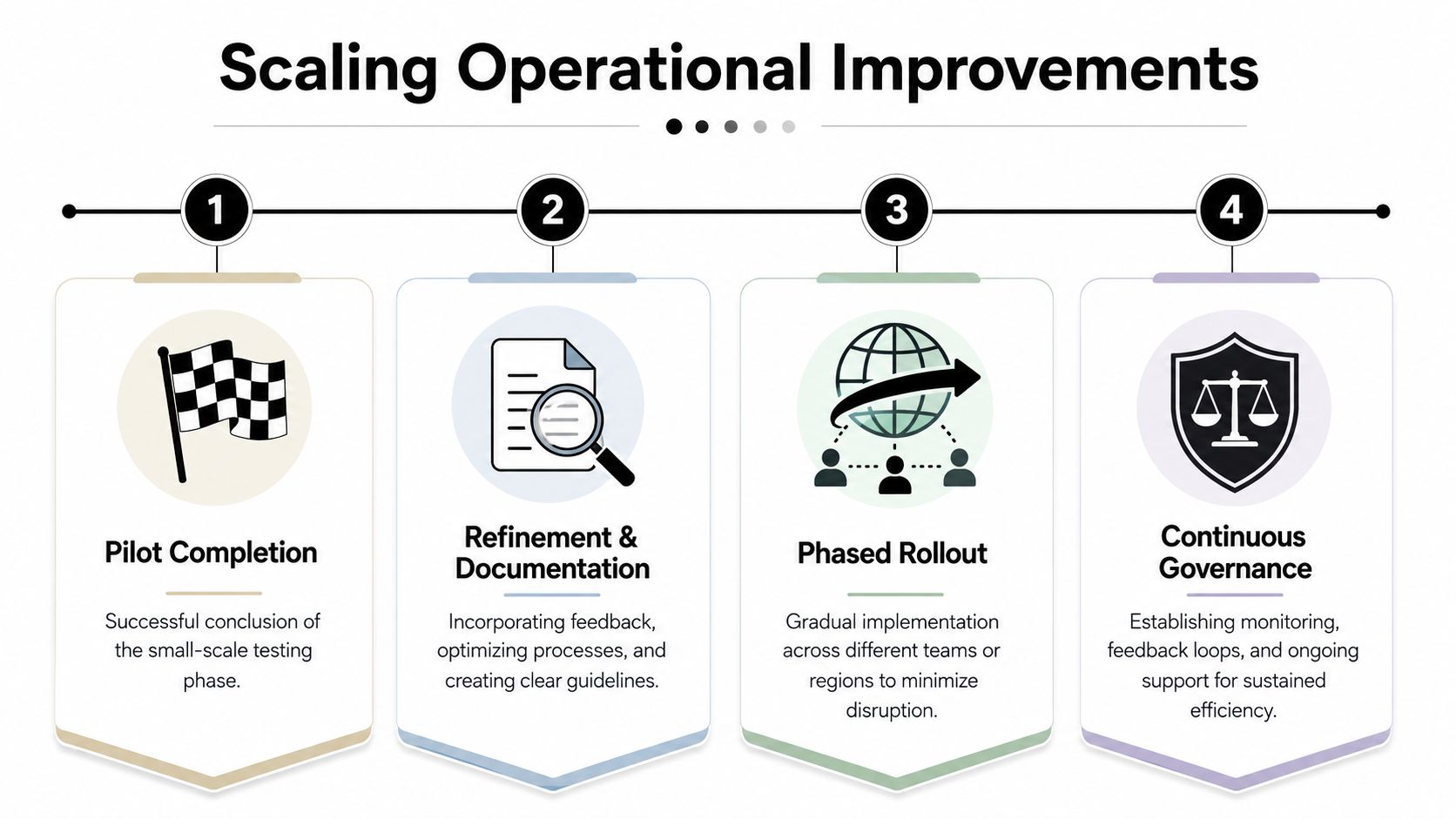
Scale in phases, not in one jump
The rollout sequence matters. Start with the teams most similar to the pilot environment. Their adoption curve is shorter, and their feedback is more actionable. Then expand to more complex teams, regions, or business units once the documentation, controls, and support model are ready.
A practical scale plan usually includes:
- Refinement after pilot: Fix workflow gaps, edge cases, and reporting blind spots.
- Documentation: Publish process steps, exception paths, ownership, and support rules.
- Phased rollout: Expand by function, geography, or process family.
- Adoption support: Give managers clear expectations and teams usable training.
Some operational guidance recommends monthly check-ins, named owners, and phased implementation over six months to prevent gains from decaying, as covered in the earlier discussion of the process-audit approach.
Avoid brittle efficiency
Many leaders get too aggressive. They remove slack, centralize decisions, automate every repeatable action, and end up with a system that breaks under pressure.
Industry reporting on modern operational efficiency argues that there's a trade-off between efficiency and resilience, and that over-optimizing can create fragile systems. The same Eliassen perspective on what operational efficiency means now notes that leaders are extending efficiency work into cloud, software, and infrastructure sprawl while using AI and automation to improve output without degrading quality or strategic flexibility.
That matters for CTOs because resilient systems need room for exceptions. Build fallback paths. Keep human escalation where judgment matters. Don't automate away your ability to respond.
The best operating model is efficient under normal load and recoverable under abnormal load.
Governance is what keeps gains from fading
Governance doesn't need to be bureaucratic. It needs to be visible.
The simplest durable model includes clear KPI ownership, a shared scoreboard, exception review, and regular process reviews. The metric set should stay tied to strategic goals, not drift into vanity reporting.
Use governance to answer four questions:
| Governance question | What leadership should know |
|---|---|
| Who owns the metric? | Accountability can't be shared across everyone |
| What changed this month? | Variance should trigger action, not just reporting |
| Where are users bypassing the system? | Workarounds usually expose design flaws |
| Which exceptions are rising? | Rising exceptions often signal a brittle process |
Without governance, operational efficiency improvement degrades into a one-time project. With governance, it becomes a repeatable management capability.
Proving ROI with a Hands-Free Partnership
The hardest part of operational efficiency improvement usually isn't finding problems. It's proving business impact in a way leadership trusts.
That's where many programs stall. Teams launch a workflow, celebrate adoption, and then struggle to connect the effort to cost, throughput, service quality, or capacity creation. The initiative starts sounding useful, but not accountable.
Most efficiency programs fail in the reporting layer
FranklinCovey highlights a common failure point in operational efficiency work: the measurement problem. Leaders often don't know which KPIs matter for a given function or how to tie them to accountability. Its guidance on operational efficiency emphasizes aligning metrics to strategic goals and using visible scoreboards so efficiency becomes a tracked outcome instead of a vague aspiration.
That diagnosis is right.
If you don't define the KPI model up front, you won't prove return later. You'll have anecdotes, not operational evidence. For a CTO, that means every initiative needs a metric chain from workflow output to business value, supported by clean pipelines and reporting foundations such as data engineering services.
Hands-free execution changes the economics
Most internal teams don't fail because they lack intent. They fail because execution competes with everything else. The same engineers responsible for delivery, maintenance, incidents, security, and platform work are expected to redesign workflows, integrate AI, manage change, instrument reporting, and train users. That's unrealistic.
A hands-free partnership solves a different problem than a software vendor does. It doesn't just supply tools. It carries the implementation burden. Leadership sets the strategy, chooses the target workflows, and approves the success metrics. The partner handles the heavy lift: workflow mapping, system integration, AI orchestration, pilot execution, adoption support, and ongoing reporting.
That model is stronger because it ties action to accountability. The work gets done. The metrics stay visible. The business can see whether the new operating model improved throughput, service performance, quality, or cost posture.
The practical standard is simple. If an efficiency partner can't show you the baseline, the intervention, and the measured outcome, they're not running an operational program. They're running an experiment.
Silicon Prime AI works as a hands-free AI transformation partner for SMEs and enterprises that need real operational efficiency improvement, not slideware. You set strategy. They carry the weight across workflow analysis, AI implementation, system integration, and measurable ROI tracking. If you want a partner that can manage the execution load while your team stays focused on core business priorities, talk to Silicon Prime AI.
Comments