Your team probably says the same thing every quarter. We need to ship faster. We need to reduce incidents. We need to modernize the stack. Then the sprint fills with production issues, dependency updates, brittle integrations, and manual release work. Innovation slips. Maintenance wins.
That's not a team discipline problem. It's a management model problem.
Most CTOs still treat software maintenance services as a necessary expense, something to contain, outsource cheaply, or bury under “run” budgets. That's backwards. Maintenance decides whether your product gets safer, faster, easier to change, and cheaper to operate over time. If you handle it well, it becomes an engine for release velocity, resilience, and better capital allocation. If you handle it poorly, it strangles your roadmap.
A stronger model is simpler than most companies make it. You set strategy. A trusted partner carries execution, keeps the platform healthy, and uses AI to remove drag before it hits customers.
Beyond Bug Fixes The Strategic Role of Software Maintenance
If you still frame maintenance as bug fixing, you're managing the wrong problem.
The long-standing 60/60 rule says around 60% of a software product's lifecycle cost goes to maintenance, and about 60% of that maintenance effort is spent on enhancements rather than bug fixing, according to O'Reilly coverage summarized by Vention. That should end the debate. Maintenance isn't a support queue. It's where product evolution happens.
A lot of leaders say they want teams focused on innovation while starving the function that makes innovation sustainable. Then they wonder why delivery slows down as the system grows. The answer is usually visible in plain sight. Unowned technical debt. Delayed upgrades. Fragile release pipelines. No clear maintenance operating model.
Maintenance is where strategic capacity is won or lost
Every platform accumulates entropy. Frameworks age. APIs change. Infrastructure drifts. Security expectations rise. Business logic grows more tangled. If nobody owns that reality with discipline, your feature velocity becomes fake. You still ship, but every release costs more attention, more coordination, and more risk.
That's why mature engineering leaders connect maintenance directly to operational efficiency improvement. The point isn't to keep the lights on. The point is to reduce the effort required to change the system safely.
Practical rule: If maintenance work never improves release readiness, you don't have a maintenance strategy. You have a repair service.
Stop buying hours and start buying operational leverage
A strong maintenance function should do four things at once:
- Protect availability: Resolve defects and keep production stable.
- Reduce drag: Remove bottlenecks in code, infrastructure, and release workflows.
- Increase adaptability: Keep the product compatible with changing environments and business demands.
- Create room to ship: Free your core team to focus on roadmap work that differentiates the business.
That last point matters most. The best software maintenance services feel almost invisible to leadership because they remove friction before it becomes an executive problem. You define priorities. The partner handles triage, upgrades, monitoring, refactoring, release hygiene, and the low-grade operational burden that would otherwise consume your engineering organization.
That's the shift CTOs need to make. Maintenance is not a cost center to minimize. It's a strategic execution layer to professionalize.
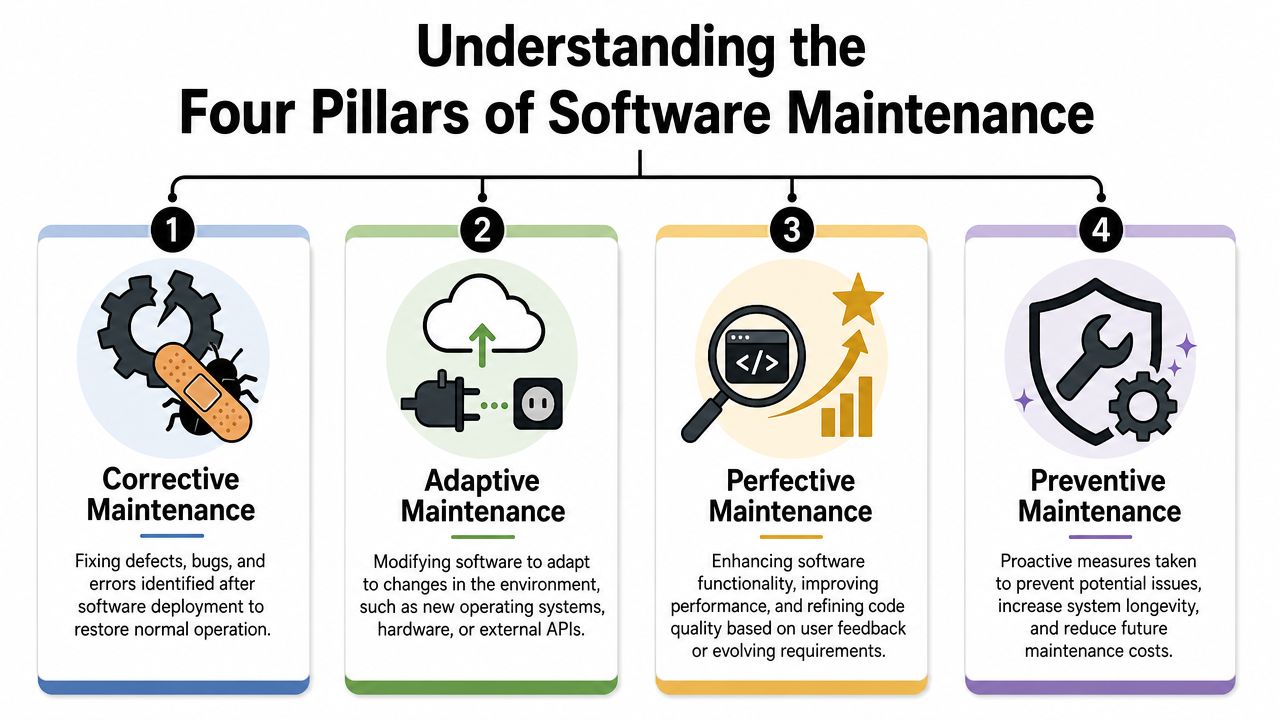
Understanding the Four Pillars of Software Maintenance
Software maintenance works best when you treat it like operating a commercial building, not a one-time construction project. You don't wait for a pipe burst to think about upkeep. You fix defects, adapt to code changes and regulations, improve the tenant experience, and prevent failures before they happen.
Why the old break-fix model fails
The cleanest framework is the classic four-part model.
- Corrective maintenance: Fix defects after release. This is the leaking pipe, failed login flow, broken webhook, or crashed job that needs immediate attention.
- Adaptive maintenance: Modify software as the environment changes. New operating systems, browser behavior, cloud services, hardware constraints, and external APIs all force updates whether you planned for them or not.
- Perfective maintenance: Improve performance, usability, and maintainability. This includes teams refactoring ugly modules, streamline user flows, reduce latency, or simplify deployment steps.
- Preventive maintenance: Reduce future failure risk before incidents happen. This includes retiring brittle dependencies, tightening observability, cleaning up technical debt, and addressing weak scaling paths.
Thales describes software maintenance as a lifecycle control function, noting that adaptive work reduces breakage from platform drift and preventive work lowers future failure risk by addressing technical debt, vulnerability exposure, and scaling bottlenecks before they become service-impacting incidents, as outlined in its guidance on the four types of software maintenance.
A lot of teams overinvest in corrective work because pain is visible there. That's understandable and still wrong. If your maintenance model is dominated by reactive ticket handling, the system keeps getting harder to operate.
For teams trying to tighten delivery, it helps to connect maintenance with release operations, environment standardization, and automation discipline. That's where focused DevOps services become part of maintenance, not a separate budget line.
How AI changes the work inside each pillar
AI doesn't replace this framework. It makes each pillar faster and more consistent.
Here's where it helps in practice:
| Pillar | AI-augmented contribution | CTO takeaway |
|---|---|---|
| Corrective | Speeds issue triage, log analysis, anomaly correlation, and draft remediation steps | Faster response with less senior engineer interruption |
| Adaptive | Flags dependency changes, API mismatches, and compatibility risks earlier | Fewer surprise breakages during upgrades |
| Perfective | Identifies inefficient code paths, repetitive maintenance work, and refactor candidates | Better use of engineering time |
| Preventive | Detects weak patterns, recurring incident sources, and signs of capacity or reliability stress | Lower operational risk over time |
Good maintenance partners don't use AI as decoration. They use it to shorten diagnosis loops, improve consistency, and keep engineers focused on higher-value decisions.
The practical payoff is simple. Humans should set priorities, review tradeoffs, and approve architecture decisions. AI should accelerate inspection, monitoring, pattern detection, and low-risk execution support. That's how maintenance stops being a backlog graveyard and becomes a continuous improvement system.
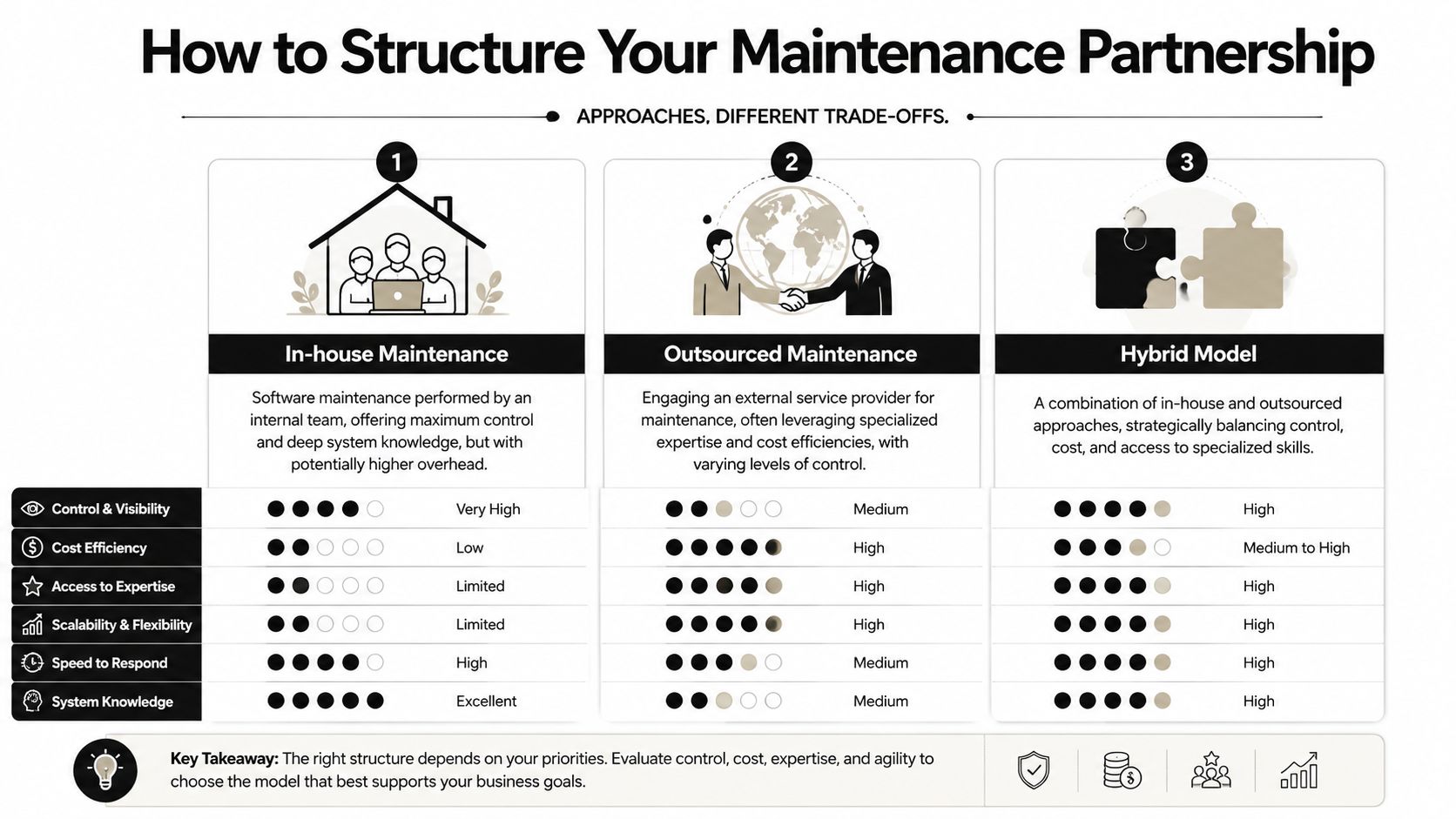
How to Structure Your Maintenance Partnership
The structure you choose will determine whether maintenance becomes an advantage or overhead. Most companies don't fail because they picked the wrong vendor category. They fail because they picked a delivery model that doesn't match the complexity of their stack and the speed of their roadmap.
Start with a visual comparison.
The real trade-off is not cost alone
Most leaders compare models on hourly rates. That's too shallow. Compare them on control, context retention, specialist access, and ability to absorb change.
| Model | Strength | Weakness | Best fit |
|---|---|---|---|
| In-house | Deep product context and direct control | Expensive attention drain on core team | Products that are highly sensitive or deeply proprietary |
| Traditional managed services | Predictable support coverage | Often ticket-driven and detached from roadmap | Commodity support needs and stable environments |
| Dedicated external team | Better continuity and stronger execution ownership | Can still become staff augmentation if poorly managed | Growing products that need sustained change capacity |
| Hybrid | Balances internal ownership with partner execution | Requires crisp governance | Most enterprise environments with mixed priorities |
The contract mechanics matter more than most CTOs expect. The U.S. General Services Administration noted that a maintenance contract negotiated at 22% of net license fees with 4% annual escalation was estimated to cost about $1 million more per year than a better-negotiated equivalent, according to its guidance on software maintenance negotiation best practices. That's not a footnote. It's a reminder that pricing structure, escalators, scope boundaries, and service definitions shape total cost far more than a polished sales pitch.
If you're evaluating external capacity, a useful comparison is the difference between team augmentation models and true execution partnerships. One gives you extra hands. The other gives you owned outcomes.
A short explainer helps here:
What a hands-free model should look like
A hands-free partnership is not “fully outsourced” in the lazy sense. It's operationally precise.
The client should own:
- Strategy and priorities: Product direction, budget guardrails, compliance requirements, and architectural principles.
- Business decisions: Which tradeoffs matter, what gets accelerated, and where risk is acceptable.
- Executive governance: Review cadence, escalation rules, and KPI approval.
The partner should own:
- Execution mechanics: Triage, maintenance planning, dependency work, release preparation, testing coordination, monitoring, and documentation.
- Delivery discipline: Clear SLAs, visible work intake, incident handling, and continuous optimization.
- AI-supported operations: Faster diagnosis, richer observability, and tighter maintenance loops.
That's the model I'd recommend for most CTOs with active products, lean internal teams, or complex environments. Don't hire a vendor to wait for tickets. Hire a partner to keep the system changing safely.
Defining Success with SLAs Pricing and KPIs
If your maintenance agreement is vague, your results will be vague too. “Responsive support” means nothing. “Flexible engagement” means nothing. You need commercial terms and operating metrics that force clarity.
One useful budgeting benchmark is that annual maintenance commonly runs at about 7% to 9% of the original development cost, with one cited example estimating $21,000 to $27,000 per year for a $300,000 system, based on Exolnet's discussion of custom software maintenance. The same source notes a practical cadence split. Application maintenance may happen every four to six months, while server maintenance is often weekly. That's a good reminder that application and infrastructure upkeep shouldn't be lumped into one generic line item.
Price the service for outcomes not motion
Two pricing models dominate most maintenance deals.
- Fixed price: Useful for tightly defined scope, known service boundaries, and routine operational work.
- Time and materials: Useful when change volume is less predictable, systems are messy, or transition work is still unfolding.
Neither is automatically better. The problem is that both can reward activity instead of progress.
A stronger agreement ties payment logic to operating behavior. Not fake “transformation” language. Real commitments like response classes, resolution ownership, deployment readiness, review cadences, and backlog burn against agreed priorities. If you're weighing models, this fixed fee versus hourly framework is the right lens. Match pricing to uncertainty, not to procurement habit.
Don't ask vendors for their rate card first. Ask what work they'll own without constant client intervention.
Track signals that show business value
Most SLA documents overweight uptime and underweight delivery quality. Uptime matters, but it doesn't tell you whether the maintenance partner is making the system easier to evolve.
Use KPIs that expose both reliability and execution quality:
- Mean time to resolution: How quickly the team closes production-impacting issues.
- Release cadence: Whether the platform is shipping on a dependable rhythm.
- Change failure rate: Whether releases create new instability.
- Backlog health: Whether low-grade maintenance debt is shrinking or just being deferred.
- Upgrade readiness: Whether dependencies, frameworks, and infrastructure stay supportable.
- Escalation quality: Whether critical issues arrive with diagnosis, options, and owner accountability.
You also want SLA language that defines ownership clearly. Who handles monitoring alerts. Who patches servers. Who validates after dependency upgrades. Who updates runbooks. Who communicates during incidents. Who approves production changes.
If the document doesn't answer those questions, you don't have an agreement. You have assumptions waiting to fail.
What to Ask Your Next Maintenance Partner
Price attracts attention. Operating maturity determines whether the relationship works.
That matters even more because neutral procurement analysis says third-party providers can cost about one-half to one-third of OEM support, while also warning that buyers often don't get a clear view of tradeoffs like security exposure or upgrade constraints, as discussed in WNS Procurement's analysis of third-party software maintenance providers. Cheap support can become expensive the moment your stack hits a security event, integration failure, or migration deadline.
Use a checklist that forces substance.
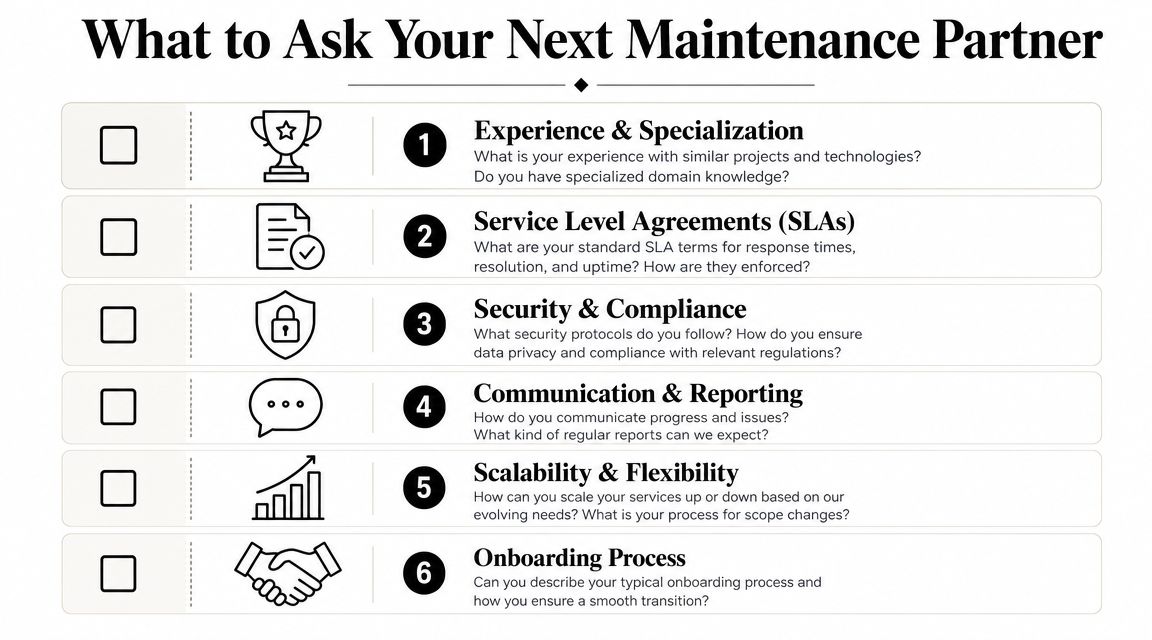
Questions that expose weak vendors fast
Ask these in the first serious call or RFP round:
- System ownership: What parts of the stack will you own directly, and what still depends on our internal team?
- Incident method: How do you detect, classify, escalate, and resolve production issues?
- Debt policy: How do you identify technical debt, prioritize it, and prevent it from compounding?
- Upgrade discipline: How do you handle framework updates, dependency changes, and API version shifts?
- Security posture: What's your process for patching, access control, auditability, and compliance support?
- Release quality: How do you increase release velocity without increasing defects?
- Reporting: What will we see weekly or monthly that tells us the service is improving the product?
- AI usage: Where exactly do you use AI in maintenance work, and where do humans retain approval authority?
If the answers sound like generic support-center language, move on.
For scope control, insist on seeing the commercial assumptions behind handoff, exclusions, approval cycles, and change requests. This guide on what's inside a fixed-fee statement of work is useful because it surfaces the clauses that often get ignored until there's a dispute.
What a strong answer sounds like
You're not looking for grand promises. You're looking for operational credibility.
A strong partner will usually show these traits:
- They speak in workflows: Intake, severity mapping, deployment checks, rollback paths, and reporting routines.
- They understand environment drift: They know maintenance includes dependencies, infrastructure, integrations, and observability.
- They distinguish ownership from assistance: They can tell you what they run and what they advise on.
- They treat documentation as a live asset: Runbooks, architecture notes, and change history are part of the service.
- They use AI with discipline: For triage, anomaly detection, analysis support, and repetitive maintenance work, not for unchecked production decisions.
If a vendor can't explain how they keep a system healthy between incidents, they're not selling maintenance. They're selling reaction time.
The Roadmap From Onboarding to Optimization
Maintenance transitions fail when they start with blind ticket intake. A proper engagement follows a sequence. First understand the system. Then take control safely. Then stabilize. Then optimize. Then align the service to business goals.
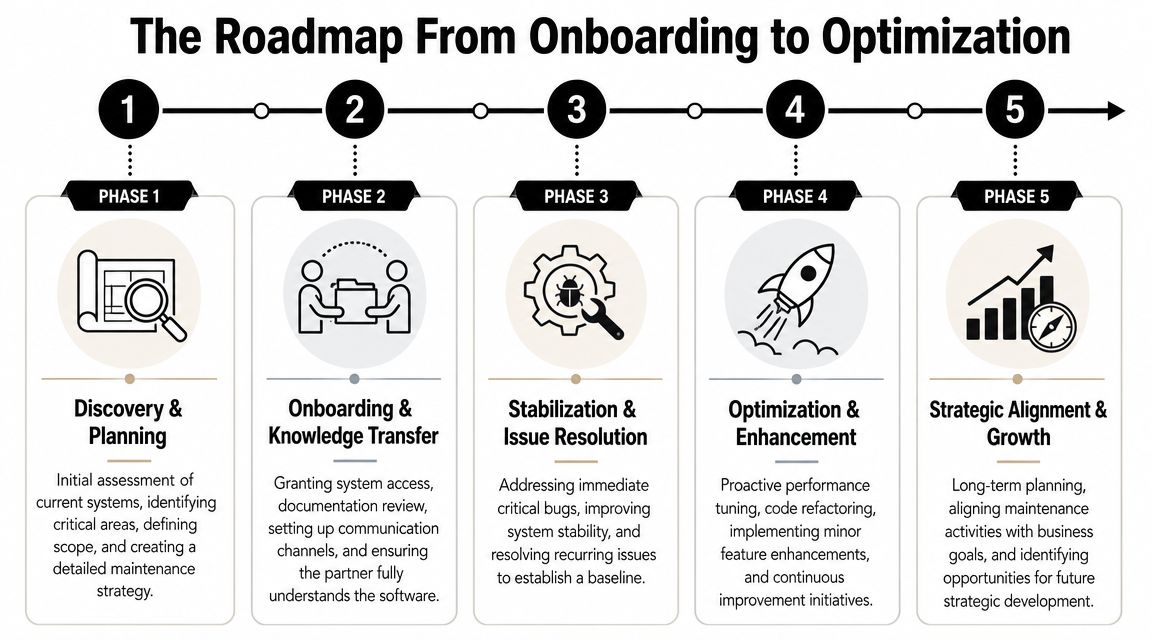
Phase one through three
Discovery and planning comes first. The partner reviews architecture, environments, deployment paths, dependencies, support history, and known risk areas. This phase should produce a maintenance strategy, not just access requests.
Onboarding and knowledge transfer comes next. Access gets provisioned. Documentation gets reviewed. Gaps get identified. Incident channels, release procedures, and approval paths are established. Good partners don't pretend the documentation is complete. They rebuild context quickly.
Stabilization and issue resolution is where credibility gets earned. The partner addresses recurring issues, production pain points, and obvious operational weaknesses. Early wins matter here. They reduce noise and create trust with internal stakeholders.
Phase four and five
Optimization and enhancement is where maintenance becomes strategic. The team starts tuning performance, cleaning brittle code paths, tightening automation, and introducing targeted improvements that reduce future effort. This is also where an AI-augmented operating method starts to pay off. Pattern detection, alert analysis, test support, and smarter triage let engineers spend more time on high-value change.
One example in this category is Silicon Prime AI, which works as a software delivery and AI transformation partner for enterprises managing active tech stacks. In a maintenance context, that kind of model fits when a company wants strategic control but doesn't want internal leaders carrying the day-to-day execution load.
Strategic alignment and growth is the final phase. Maintenance planning connects directly to roadmap decisions, budget timing, modernization priorities, and business risk. At that point, the partner isn't just preserving the system. They're helping shape what the system can support next.
The sequence matters because it keeps maintenance from collapsing into random task handling. It gives the CTO a controlled path from handoff risk to durable operational advantage.
Your Hands-Free Partnership for Software Delivery
The old maintenance model is too narrow for the systems most companies run now. It assumes software is mostly stable, change is intermittent, and support is reactive. That's no longer true.
Under AI-era operating conditions, maintenance has to cover model drift and API changes, not just application code, and the industry is shifting from break-fix support to proactive monitoring, optimization, and refactoring for long-term reliability, as described in Unthinkable's perspective on software maintenance and support services. If your product includes AI features, third-party services, or fast-moving integrations, the maintenance layer becomes even more important.
That's why I'd advise CTOs to stop asking one narrow question. “How do we reduce maintenance cost?” Ask a better one instead. “How do we turn maintenance into a force multiplier for release quality, adaptability, and engineering focus?”
The answer is a hands-free partnership model.
You set strategy. You define business priorities, architectural guardrails, risk tolerance, and budget constraints. Your partner carries the weight. They run the maintenance engine, absorb the operational burden, and use AI where it improves speed, consistency, and visibility. Your internal team stays focused on differentiated work.
That model is better than in-house firefighting. It's better than passive managed services. And it's much better than paying for a ticket queue that never improves the system behind the tickets.
Buy software maintenance services the way you'd buy any strategic capability. Demand ownership. Demand operational clarity. Demand evidence of disciplined execution. Demand a partner that makes the system easier to change after every month of service, not harder.
That's where ROI comes from. Not from lower hourly rates. From a platform that keeps moving without dragging your best people into constant repair work.
If you want a software partner that can help your team manage maintenance, modernization, and AI-enabled delivery without adding operational drag, talk to Silicon Prime AI. The right engagement should let your leadership team set direction while the delivery partner handles the execution load with discipline.
Comments