Your cloud estate probably didn't become complex all at once. It happened one product launch, one urgent integration, one regional deployment, and one “temporary” cloud account at a time. Now the team that was supposed to drive new revenue is also chasing alerts, reviewing spend anomalies, fixing access drift, and answering the same operational questions every week.
That's the point where cloud infrastructure management stops being a tooling problem and becomes a leadership problem. The issue isn't whether your engineers are capable. It's whether your operating model lets them focus on work that moves the business forward while someone reliable carries the day-to-day weight of the platform.
The Growing Complexity of Modern Cloud Environments
The cloud was supposed to simplify infrastructure. At small scale, it often does. Teams can provision quickly, test ideas without waiting on hardware, and support new workloads without a procurement cycle slowing them down.
At enterprise scale, the reality changes. Speed creates sprawl. Sprawl creates inconsistency. Inconsistency creates risk, wasted spend, and a lot of operational drag that doesn't show up in architecture diagrams.
A useful way to read the market is this. Organizations aren't treating cloud operations as a temporary transition phase anymore. One market forecast places the cloud infrastructure services market at USD 166.51 billion in 2025, rising to USD 194.82 billion in 2026, with a projection of about USD 766.57 billion by 2035 and a 16.50% CAGR from 2026 to 2035 according to Precedence Research's cloud infrastructure services market forecast. That kind of scale usually points to a permanent operating layer, not a short-lived adoption wave.
Cloud management becomes mission-critical when the business starts depending on cloud speed, but the team is still running operations like an ad hoc side job.
I've seen this pattern in fast-moving environments where central operations teams support many sites, systems, and stakeholders at once. The pressure isn't abstract. It shows up in handoffs, stale dashboards, fragmented ownership, and slow incident response. That operating tension is visible in this field visit to a 400-location operations center, where scale turns small process gaps into recurring business issues.
Why complexity grows faster than expected
- Teams add services under pressure: A new region, vendor, or application lands quickly, but governance usually arrives later.
- Different groups optimize locally: Platform, security, finance, and product all make sensible decisions. Those decisions don't always align across the estate.
- Temporary choices become permanent: Test environments, emergency permissions, and one-off automations tend to linger.
The result is familiar. Leaders spend too much time asking who owns what, why costs moved, whether controls are consistent, and how much operational risk they're carrying. That's exactly where cloud infrastructure management services matter most.
What Are Cloud Infrastructure Management Services
Cloud infrastructure management services are the operating layer that keeps your cloud environment reliable, secure, cost-aware, and aligned to policy after the initial deployment is done. They're not the same thing as renting raw cloud resources. They sit above those resources and make them workable at scale.
Think of it as digital property management
A simple analogy helps. If your company owns a portfolio of buildings, ownership alone doesn't keep those properties useful. Someone still has to handle maintenance, access, compliance, utilities, tenant issues, upgrades, and emergency response.
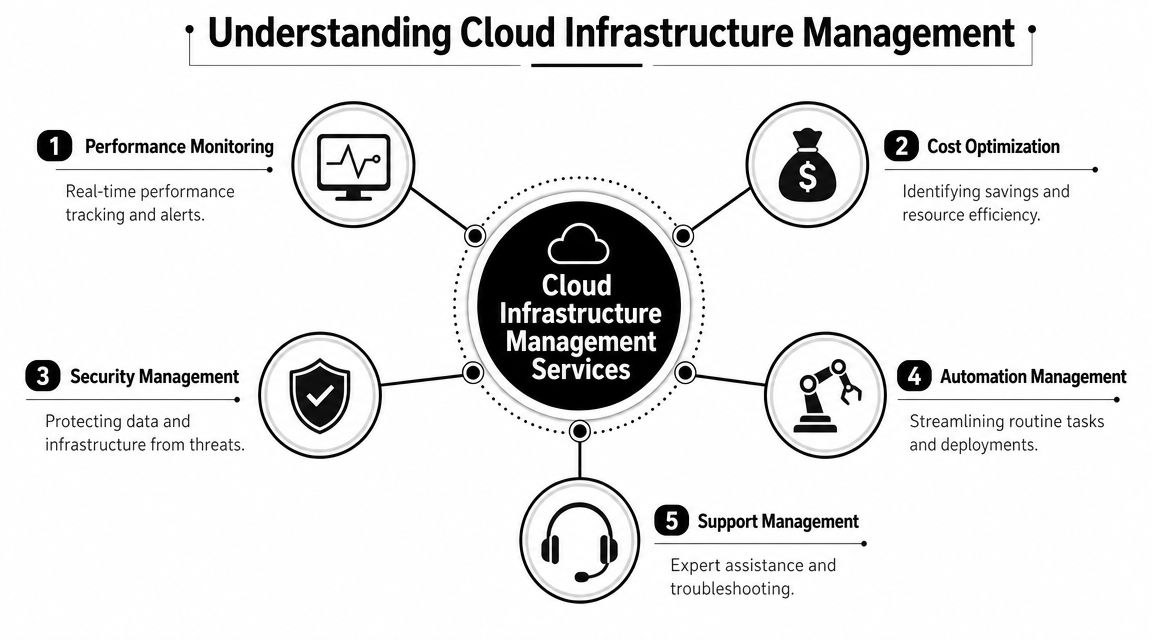
Cloud works the same way. Your infrastructure may live in AWS, Azure, Google Cloud, a private environment, or a mix of all of them. But someone still has to:
- Monitor performance: Watch workloads, dependencies, logs, and alerts in real time.
- Control costs: Tag resources, review waste, right-size environments, and allocate spend accurately.
- Enforce security: Manage identities, permissions, patching, secrets, and baseline controls.
- Automate routine work: Provision consistently, apply policy through code, and reduce manual drift.
- Support operations: Investigate incidents, execute runbooks, and keep services available.
Where these services sit in the stack
Most organizations run across several service layers, and management has to span all of them.
| Layer | What it provides | What management services do |
|---|---|---|
| IaaS | Compute, storage, networking, virtual machines | Provisioning, monitoring, patching, access control, backup, cost governance |
| PaaS | Managed runtime platforms and developer services | Configuration oversight, policy enforcement, integration management, usage review |
| CaaS | Container platforms and orchestration environments | Cluster operations, workload scaling, deployment controls, observability, security posture |
The practical point is that cloud infrastructure management services create a unified control model across these layers. Without that model, teams end up with one set of rules for virtual machines, another for containers, and a third for managed services. That's when outages become harder to diagnose and policy becomes hard to trust.
A mature provider doesn't just “watch dashboards.” The provider builds operating discipline into the platform through runbooks, automation, escalation paths, and engineering support. If you want to see how that discipline overlaps with delivery practices, the work often sits close to a broader DevOps services model rather than a narrow help-desk function.
Why a Managed Partnership Unlocks Business Value
A managed model works when it gives leadership more control, not less. That sounds counterintuitive until you've lived the alternative. In-house teams often own the cloud formally but spend so much time on operational chores that strategic control slips away anyway.
The best managed partnerships remove burden while preserving decision rights. Your leadership team sets architecture direction, security posture, risk tolerance, and business priorities. The operating partner handles the repeatable, time-consuming, high-consequence work required to keep that strategy functioning day after day.
Focus returns to the product team
Engineering talent is expensive and hard to replace. It shouldn't be consumed by routine environment upkeep, recurring incident triage, or manual compliance checks that could be automated and operationalized.
When a strong partner owns the run layer, internal teams can spend more time on work such as:
- Shipping product changes: New features, integrations, and customer-facing improvements.
- Improving architecture: Refactoring brittle services, modernizing pipelines, and reducing technical debt.
- Supporting growth initiatives: New markets, acquisitions, AI workloads, and data-intensive services.
Practical rule: If your best engineers are spending their week on patch windows, tag cleanup, and reactive cloud support, your operating model is too expensive even if the budget spreadsheet says otherwise.
Cost, security, and execution improve together
Cloud cost optimization isn't just a finance exercise. It depends on architecture quality, environment hygiene, ownership clarity, and deployment discipline. A managed partner can make those things routine.
Security benefits from the same model. Strong security in the cloud is operational. It depends on continuous enforcement, not annual intent. Identity controls, patching, configuration baselines, secret handling, backup integrity, and audit readiness all need active ownership.
A good partnership also improves execution quality because responsibilities stop bouncing between teams. Issues get routed through defined runbooks. Alerts have owners. Changes follow repeatable procedures. Leadership gets clearer reporting and fewer surprises.
A useful test is whether the relationship feels like delegated accountability or just outsourced labor. If it's the latter, you'll still carry most of the cognitive load internally. If it's the former, your partner behaves like an extension of operations leadership and protects your team's focus. That's the difference between buying hours and using a true managed application services partner.
Anatomy of a World-Class Management Service
Not all cloud infrastructure management services are built the same. Some providers offer little more than ticket handling and after-hours escalation. A world-class service runs the environment with discipline, automation, and enough technical depth to prevent recurring problems instead of just responding to them.
What strong operators put in place
The first sign of quality is proactive monitoring. That means the provider isn't waiting for a business user to notice something is wrong. They've instrumented the platform, tuned alerts, connected logs and metrics to meaningful thresholds, and built escalation paths that reflect business criticality.
The second sign is automation with intent. Good providers don't automate for appearances. They automate the tasks that create the most risk when handled manually: provisioning, patching, policy enforcement, backup workflows, and routine remediation. Infrastructure as code matters here because it gives teams a repeatable system of record.
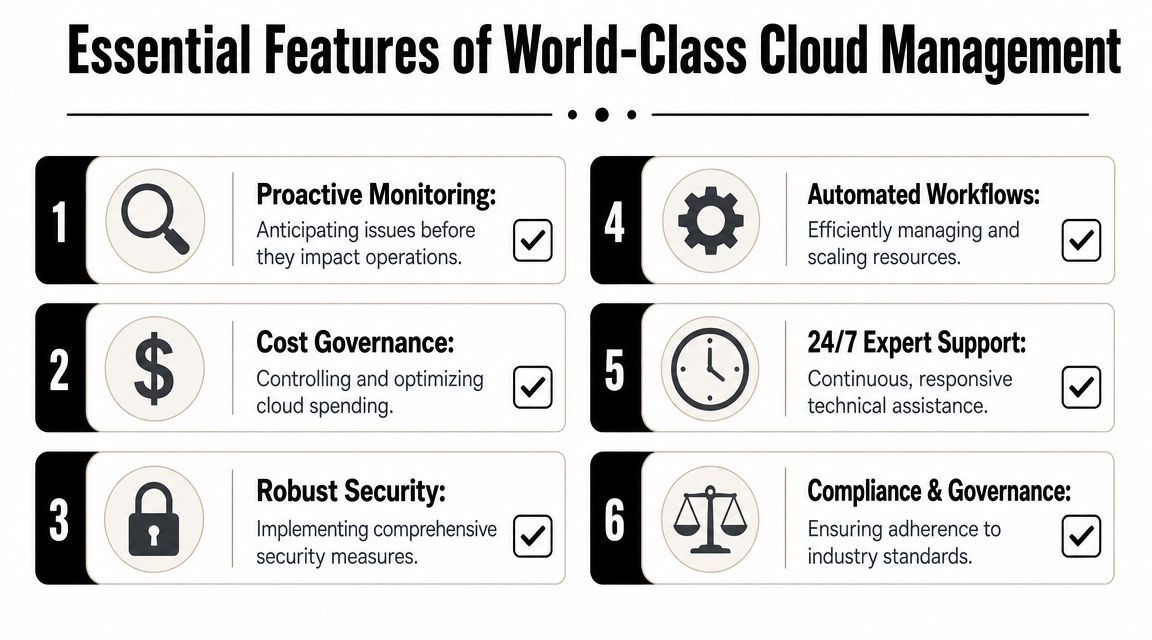
A serious service usually includes:
- Operational observability: Metrics, logs, tracing, alert tuning, and service health visibility.
- Cost governance: Tagging discipline, budget ownership, waste reviews, and placement decisions.
- Security operations: Access reviews, patch baselines, secrets handling, vulnerability response, and guardrails.
- Resilience planning: Backup validation, recovery procedures, environment redundancy, and failover runbooks.
- Expert support: Engineers who can troubleshoot infrastructure, not just forward tickets.
- Compliance alignment: Policy enforcement, evidence collection, and auditable change practices.
Why interoperability matters
Many organizations now manage more than one cloud, more than one orchestration layer, and more than one operational toolchain. That's why interoperability matters so much. If your management model only works inside a single vendor's worldview, your governance becomes fragile the moment the environment expands.
The DMTF Cloud Management Initiative exists to promote standards for interoperable cloud infrastructure management, including standardized management interfaces and policy models. The goal is to make governance and automation more portable across environments, which helps reduce configuration drift and lowers the risk of being trapped by one control plane. That's described by the DMTF cloud standards initiative.
A provider's tooling matters. Their operating model matters more. If they can't carry policy, automation, and visibility across environments, they're managing a vendor console, not your cloud estate.
A world-class provider understands that the tooling stack may include Terraform, Kubernetes, native cloud controls, SIEM platforms, backup systems, and internal workflow tools. Their job is to make those pieces behave like one governed system. That's how operational overhead falls and release confidence rises.
The AI Revolution in Cloud Operations
AI has a place in cloud operations, but only when it solves operational problems that humans struggle to solve consistently at scale. Used well, it helps teams detect anomalies faster, route issues more intelligently, prioritize noisy alerts, recommend resource changes, and keep workflows moving without adding more dashboards for engineers to ignore.
AI is useful when it removes operational drag
Most cloud teams don't have a shortage of data. They have a shortage of context and action. Metrics are available. Logs are available. Security signals are available. The hard part is turning those signals into timely decisions without burning out the team.
That's where AI can help in practical ways:
- Signal reduction: Grouping related events so engineers don't triage the same incident five different ways.
- Pattern detection: Spotting configuration drift, unusual behavior, or demand changes before they become visible outages.
- Operational assistance: Supporting runbooks, summarizing incident context, and accelerating handoffs between teams.
- Cost insight: Highlighting inefficient usage patterns and prompting review before waste becomes normalized.
Used poorly, AI creates another layer of noise. Used properly, it acts as an operational amplifier for experienced engineers.
What proof of work should look like
If a provider says they use AI, ask what changed in the operating model because of it. “We use AI” isn't proof. Proof looks like workflows that are more consistent, incident response that is more structured, review cycles that are shorter, or operational knowledge that is captured and reused instead of trapped in individual heads.
The strongest implementations keep humans in charge. They use AI to improve detection, recommendation, and execution support, while engineers retain authority over production-impacting decisions and policy boundaries.
One practical example is using AI within release and infrastructure workflows, where automation can evaluate changes, assemble context, and support safer handoffs without pretending to replace engineering judgment. That approach is visible in this Aegis AI release pipeline overview, where AI is embedded into delivery operations instead of being bolted on as a separate novelty.
For teams evaluating this space, it helps to see the operational philosophy in motion:
The key distinction is simple. AI should reduce toil, improve clarity, and strengthen execution. If it adds opacity, weakens accountability, or creates new manual review burdens, it isn't helping your cloud operations no matter how modern the demo looks.
How to Select the Right Cloud Management Partner
By the time most organizations start looking for a partner, they already know the cloud is too important to run informally. The harder question is who can manage it without creating a new dependency problem.
A useful starting point is the shape of the modern estate. An industry article reports that over 85% of enterprises use a multi-cloud strategy and that the average organization uses more than five different cloud services, which is why governance, tagging, cost allocation, and security controls become harder to maintain across environments, as noted in Network Right's discussion of cloud infrastructure management. If your environment already spans multiple platforms or likely will soon, partner evaluation has to center on complexity handling, not just hourly support coverage.
Questions that expose real capability
Start with scenario questions, not feature questions. Most providers can say they offer monitoring, automation, and security support. Fewer can explain how they'd take over an inherited environment with weak tagging, inconsistent IAM practices, and poor runbook quality.
Ask questions like these:
- How do you establish operational visibility in an inherited environment?
- What do you standardize first when governance is inconsistent?
- How do you handle multi-cloud policy enforcement without relying on one vendor's native tooling?
- What's your process for cost allocation when ownership is unclear?
- How do you document and improve runbooks over time?
Don't buy a promise of “hands-free” service unless the provider can show how they take responsibility for ambiguity, not just for tickets.
What a healthy partnership looks like
A strong partner is transparent about boundaries. They should define what they own, what stays with your internal team, how escalations work, and which decisions require business approval.
Look for evidence in five areas:
| Evaluation area | What good looks like | Warning sign |
|---|---|---|
| Technical depth | Comfortable across cloud platforms, containers, IaC, security, and observability | Narrow expertise tied to one toolset |
| Operating discipline | Clear runbooks, change management, incident workflows, and reporting cadence | Heavy reliance on heroics |
| Commercial clarity | Understandable pricing, ownership definitions, and service boundaries | Vague packaging and surprise charges |
| Governance maturity | Tagging, access control, policy enforcement, audit readiness | “We can figure that out later” |
| Working style | Collaborative, direct, and accountable | Defensive or opaque communication |
A capable partner should also welcome executive scrutiny. They shouldn't resist questions about service levels, reporting, or responsibility mapping. Mature operators expect those questions because they know governance is part of the service.
If you want a useful benchmark for the kind of governance thinking procurement and technology leaders should demand, this governance memo for CIOs is close to the right standard. The right partner won't just keep systems running. They'll make the operating model easier to trust.
Your Roadmap to a Hands-Free Cloud Environment
A hands-free model doesn't mean leadership disappears. It means leadership stops carrying work that should be systematized and delegated. The transition usually works best when it follows a structured path rather than a rushed handoff.
A practical transition path
The first phase is discovery and assessment. The incoming team reviews accounts, workloads, access models, network patterns, deployment processes, tooling, and cost visibility. The point isn't to produce a giant slide deck. It's to establish a truthful picture of the current state.
The second phase is strategy and operating design. In this phase, responsibilities get defined. Governance standards, runbooks, alert ownership, backup policies, escalation paths, and automation priorities are agreed. Leadership sets direction. The partner translates that direction into an operating model.
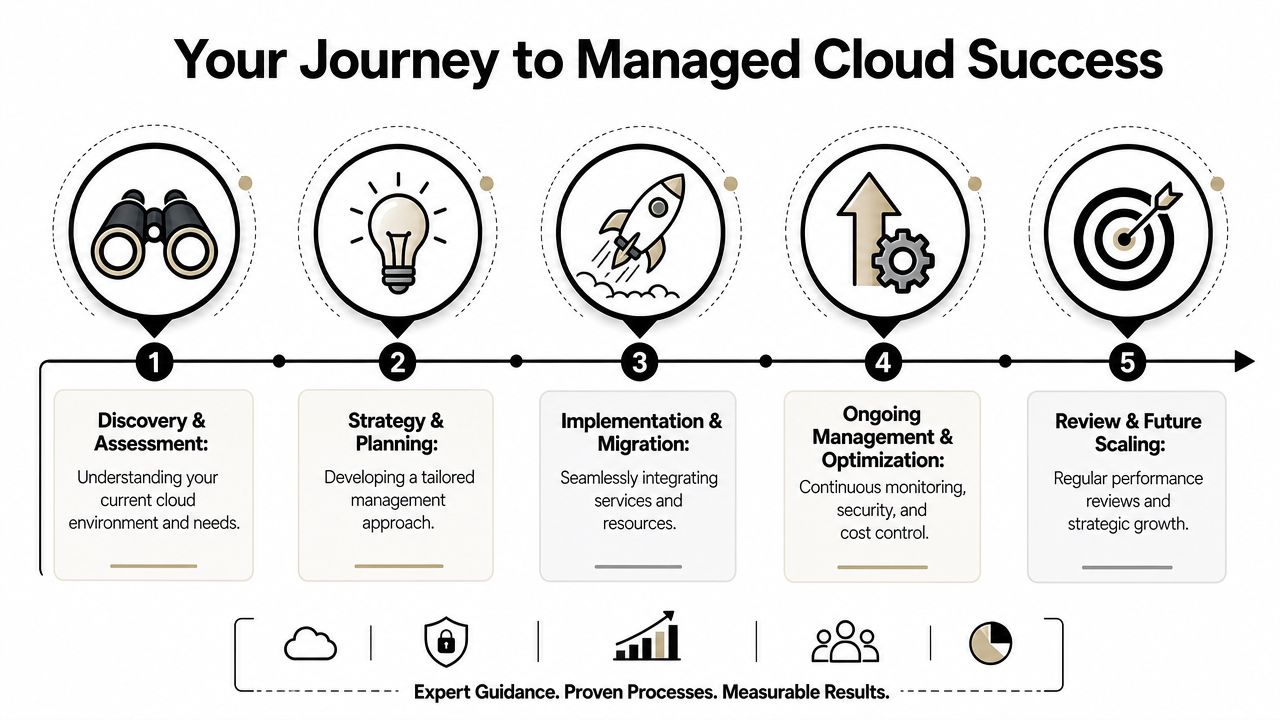
The third phase is implementation and takeover. Monitoring gets tuned. Access gets cleaned up. Automation gets introduced. Documentation improves. The provider starts handling core operational responsibilities while reducing risk in the inherited environment.
What you own and what your partner owns
The final phase is steady-state management and optimization. That's where the value compounds. Reviews become more strategic because the operating basics are no longer in question. The partner manages the platform continuously, and leadership can focus on roadmap, investment priorities, and risk decisions.
A clean model usually looks like this:
- You own business priorities: Product direction, compliance requirements, risk tolerance, architecture choices, and budget intent.
- Your partner owns execution weight: Monitoring, maintenance, operational response, cloud hygiene, optimization routines, and day-to-day platform reliability.
- Both sides share improvement: Quarterly reviews, roadmap alignment, tooling changes, and future scaling decisions.
That's what “You set strategy, we carry the weight” should mean in practice. Not distance. Not abdication. Clear leadership on your side, dependable execution on theirs.
If your team is spending too much time operating the cloud and not enough time using it to move the business forward, Silicon Prime AI can help you build a managed model that combines disciplined cloud operations with practical AI-enabled execution. The goal is simple. You keep control of strategy, priorities, and outcomes. We carry the operational weight required to make that strategy work every day.
Comments