Your AI roadmap probably looks fine on paper. The problem is your data stack probably doesn't.
You've got data in a CRM, product database, support platform, spreadsheets, ad systems, maybe a warehouse someone stood up two years ago, and a few brittle pipelines that only one engineer understands. Meanwhile, the business wants forecasting, copilots, personalization, anomaly detection, and executive dashboards that don't contradict each other. So AI pilots stall, analytics trust drops, and every new request becomes another custom integration project.
That's why data engineering services matter. Not as a back-office technical function, but as the operating foundation for AI readiness. If your data isn't reliable, governed, and continuously usable, your AI strategy is theater. If it is, AI stops being a slide deck and starts becoming an execution advantage.
The companies getting this right aren't buying random tooling and hoping for the best. They're treating data engineering as a managed capability with clear ownership, operating discipline, and a partnership model that removes execution drag. A useful example of that broader operating mindset shows up in this end-to-end AI release pipeline view, where delivery discipline matters as much as the model itself.
Beyond Pipelines Redefining Data Engineering Services
Many organizations still describe data engineering services as “building pipelines.” That definition is too small and too technical. Pipelines are only one mechanism. The actual job is creating a dependable data operating layer the business can trust for analytics, automation, and AI.
That distinction matters because a lot of companies are data-rich and decision-poor. They collect plenty of records, events, and documents, but they can't turn them into durable business logic. Revenue teams see one number, finance sees another, product teams create their own extracts, and the AI team spends more time fixing source data than building anything valuable.
The market itself reflects how central this function has become. Mordor Intelligence projects the global big data engineering services market at USD 105.38 billion in 2026, reaching USD 213.07 billion by 2031 at a 15.12% CAGR, with North America holding 42.38% share in 2025. That isn't a niche services category. It's a signal that enterprises now treat data engineering as core infrastructure for growth.
Data engineering is the prerequisite for AI credibility
If your model outputs depend on stale joins, duplicate customer records, undefined metrics, or access rules nobody can explain, your AI initiative is already compromised. Better prompting won't save bad foundations. Neither will a bigger model budget.
What modern data engineering services deliver is:
- Connected source systems so CRM, ERP, product, marketing, finance, and third-party data stop living in separate realities.
- Clean transformation logic so “customer,” “order,” “churn,” or “active user” mean one thing across teams.
- Governed access paths so people and systems get the data they need without creating compliance and security chaos.
- AI-ready structure so downstream teams can use trusted datasets for feature creation, retrieval pipelines, reporting, and operational workflows.
Practical rule: If the business can't agree on the input data, it won't trust the output of AI.
The strategic lens CTOs should use
Treat data engineering services as a capability that reduces execution friction across the company. Good data engineering shortens the distance between a business question and an operational answer. It also lowers the cost of change because new analytics, automations, and AI use cases don't require starting from scratch every time.
That's the shift many leadership teams need to make. Don't ask, “Who can build us some pipelines?” Ask, “Who can create a reliable data foundation our teams can build on without constant intervention?” The first question buys motion. The second buys advantage.
The Anatomy of a High-Performance Data Engine
A strong data platform works like a high-performance engine. Every component has a job. If one part is poorly designed, the whole system runs rough, burns budget, and fails under load. CTOs don't need to master every implementation detail, but they do need to understand the major components well enough to challenge weak designs.
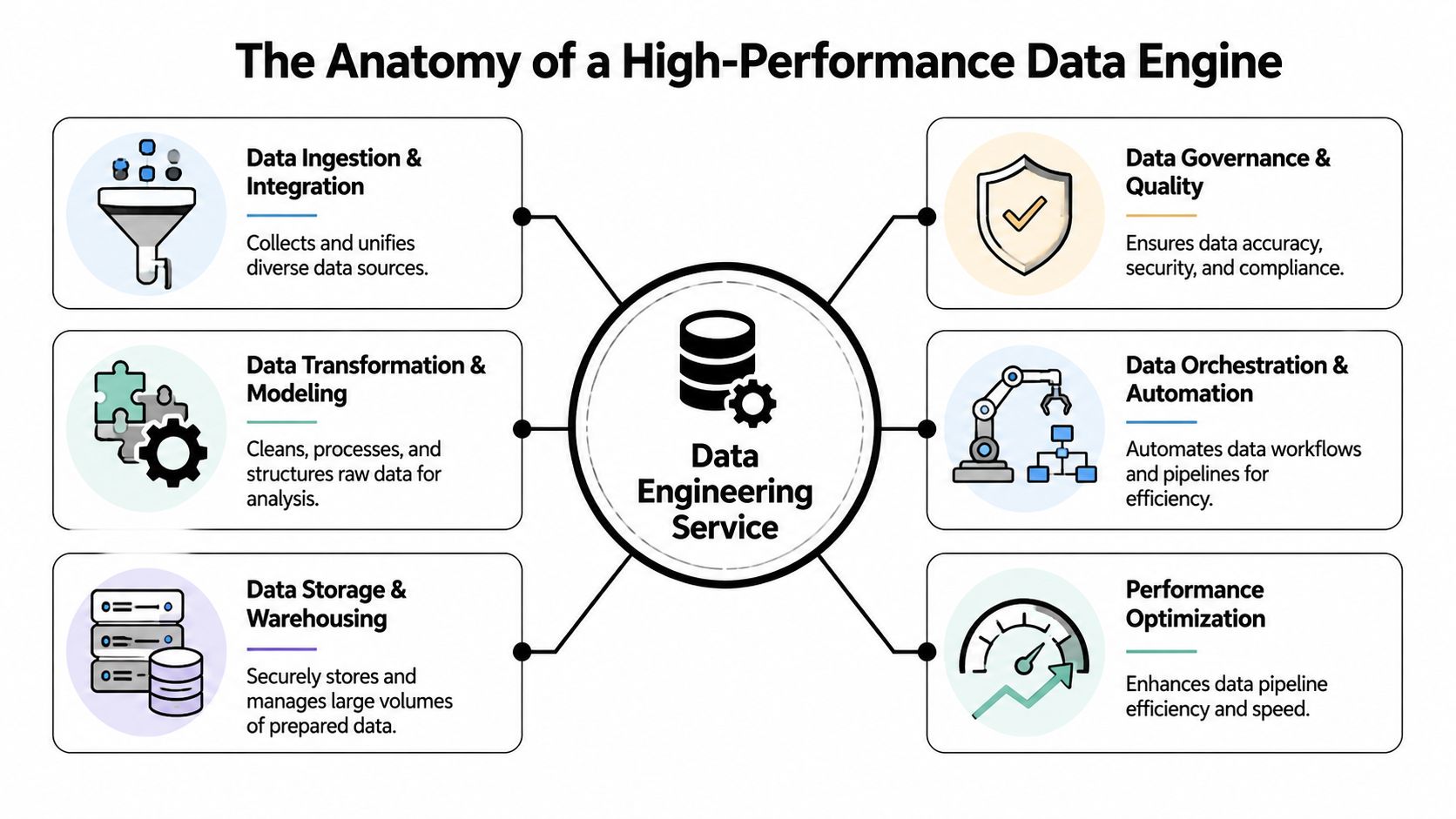
A capable partner should be fluent across cloud and data tooling, not attached to a single favorite stack. That matters when your environment spans warehouse platforms, orchestration, streaming, and transformation frameworks across teams. A broad baseline is table stakes, which is why technical depth across enterprise data and AI technologies matters more than a polished pitch deck.
The intake layer
The engine starts with ingestion and movement. Through these processes, source systems enter the platform through replication, scheduled batch jobs, event streams, APIs, file drops, or a combination of them. The wrong pattern here creates downstream pain for years.
Databricks notes that data engineering services must choose between replication, batch, streaming, or hybrid architectures, and that hybrid designs are often essential for enterprises that need both real-time operational feeds and historical analytics. In practice, that means you shouldn't let anyone force a false choice between “real time” and “warehouse reporting.” Mature environments usually need both.
A quick way to frame the options:
| Architecture choice | Best fit | Tradeoff |
|---|---|---|
| Replication | Operational copies of source systems | Can spread bad source design if unmanaged |
| Batch | Reporting, finance, historical analysis | Lower freshness |
| Streaming | Operational AI, alerts, event-driven workflows | Higher operational complexity |
| Hybrid | Mixed analytics and operational use cases | Requires stronger governance and orchestration |
The transformation layer
Raw data isn't business-ready. It's just extracted exhaust until someone applies logic to it.
This layer includes ETL, ELT, modeling, testing, and semantic design. Whether you use Spark, dbt, SQL transformations, Python workflows, or lakehouse patterns, the objective stays the same: convert messy source records into trusted entities the business can use.
The strongest teams define clear transformation ownership:
- Source-aligned ingestion models keep raw copies faithful and traceable.
- Core business models standardize customers, products, orders, subscriptions, claims, or assets.
- Consumption models shape data for finance reporting, product analytics, ML features, or executive dashboards.
The control layer
Weak vendors often get exposed. They'll talk about pipelines and warehouses, then gloss over governance, quality checks, orchestration, observability, and performance tuning. Those aren't extras. They're what make a platform usable after launch.
A platform isn't production-ready when the first dashboard loads. It's production-ready when failures are visible, ownership is clear, and remediation is routine.
The control layer should cover:
- Governance and access control for role-based permissions, sensitive data handling, and auditability
- Quality validation for schema drift, null spikes, duplicate records, and business-rule exceptions
- Orchestration using tools such as Airflow, Dagster, or managed schedulers to coordinate dependencies
- Performance optimization for warehouse costs, query speed, partitioning, storage formats, and compute scaling
That's what a finished engine looks like under the hood. Not just movement, but usable structure and controlled operation.
Your Hands-Free Partnership Model
Most CTOs don't need more random hands on keyboards. They need fewer moving parts, clearer accountability, and a team that can carry delivery without constant supervision.
That's the difference between traditional outsourcing and a hands-free partnership model. One gives you extra labor. The other gives you execution capacity with leadership wrapped around it.

Why staff augmentation falls short
Staff augmentation sounds flexible, but it often pushes integration burden back onto your leaders. You still have to define architecture, manage priorities, review delivery, align quality standards, and clean up handoff problems between contractors and internal teams. You're paying for capacity while keeping most of the management overhead.
That's a bad trade when the labor market is already tight. ElectroIQ says the global data engineering field is expected to grow by 35% in 2025, with about 260,000 job openings in the United States alone and an average annual salary of USD 124,000 for data engineers. If hiring is expensive and demand is rising, you shouldn't respond by creating a fragmented delivery model that consumes even more management time.
A better model keeps strategy inside your business and moves execution burden to a partner that owns outcomes. Your team sets priorities, approves architecture direction, defines governance boundaries, and ties work to business goals. The partner handles delivery mechanics.
What a real partnership looks like
A real data engineering partnership should feel like this:
- You own the roadmap. Business priorities, domain context, risk tolerance, and executive alignment stay with your leadership team.
- The partner owns delivery. Data architects, platform engineers, analytics engineers, QA, and delivery leadership manage build and run responsibilities.
- Both sides share governance. Security, access, change control, and data policy aren't outsourced blindly. They're enforced collaboratively.
- Operations continue after launch. Monitoring, issue response, platform evolution, and data quality management stay active instead of ending at handover.
That's why managed operating models are usually stronger than one-off implementation projects. If you want a reference point for that service posture, look at how managed application services are structured around continuity, not just delivery milestones.
Where AI-augmented delivery helps
The practical value of an AI-augmented delivery model isn't hype. It's speed, consistency, and lower manual drag across repetitive engineering work. Teams can accelerate specification, testing discipline, documentation, issue triage, migration planning, and release coordination when they use AI in a controlled way.
The key is controlled. AI should strengthen engineering process, not bypass it.
Here's a useful example of what a disciplined delivery posture looks like in practice:
What good looks like: Your internal team spends time on business logic, policy, and product priorities. The partner handles implementation detail, run-state maintenance, and execution coordination.
A hands-free partnership doesn't mean abdication. It means your leaders stop carrying unnecessary execution weight. That's the model that supports AI transformation. You keep control of intent. The partner carries the operational load.
Choosing the Right Technology Stack
The wrong way to choose a stack is to start with vendor logos. The right way is to start with constraints.
If your team already runs heavily on AWS, forcing a greenfield GCP-centric architecture better be justified. If your compliance posture depends on strict access boundaries and controlled data residency, your tooling decisions should reflect that from day one. If your analysts live in SQL and your engineers are thinly staffed, don't approve a design that requires a niche skill set just to maintain daily transformations.
A useful first step is an AI readiness assessment that checks your current data estate, governance maturity, stack fit, and operational gaps before anyone proposes a target architecture. That prevents the common mistake of buying tools before defining capability requirements.
Start with constraints, not logos
The stack should match the business you have, not the architecture someone wants to show off.
Here are the constraints that matter:
- Existing cloud commitments. AWS, Azure, and Google Cloud each offer strong data services, but the best choice is often the one that fits your identity model, networking posture, procurement path, and current workloads.
- Latency requirements. If you need event-driven automation or operational AI, you'll likely need streaming infrastructure such as Kafka or managed event services. If most use cases are finance and reporting, a batch-led design may be enough.
- Team operating model. A lean internal team should favor maintainable patterns. dbt, warehouse-native transformation, and managed orchestration may be smarter than a sprawling custom Spark estate.
- Data diversity. Structured tables, semi-structured events, documents, images, logs, and ML features don't all belong in the same serving pattern.
- Security and governance. Access control, masking, lineage, auditability, and environment separation should be native considerations, not future tasks.
A practical selection lens
Don't ask whether a tool is “modern.” Ask whether it reduces long-term operating friction.
Consider this simple evaluation frame:
| Decision area | Strong choice when | Risk signal |
|---|---|---|
| Warehouse or lakehouse | You need scalable analytics with clear governance | Tool chosen because it's trendy |
| Spark or warehouse-native compute | Data volume or transformation complexity justifies it | Engineers reach for distributed compute by default |
| Kafka or event infrastructure | Business processes depend on real-time events | “Real time” has no defined use case |
| dbt or transformation framework | You want testable, versioned analytics engineering | Logic remains trapped in dashboards |
| Managed services or self-hosted | You want less infrastructure burden | Team lacks bandwidth but chooses more ops work |
The best stack is the one your team can operate predictably for years. That usually means a deliberate mix of managed cloud services, proven open-source components, and clear standards for where custom engineering is worth it.
Measuring What Matters KPIs and Security for Data Platforms
If you can't measure platform health, you can't manage it. If you can't secure it, you can't scale it. Those are the two board-level realities behind every serious data engineering program.
Too many teams stop at delivery milestones. Pipeline built. Warehouse live. Dashboard shipped. None of that proves the platform is creating business value or controlling risk. CTOs need an operating scorecard, not a project status update.
Track operating health first
Start with platform KPIs that expose reliability and maintainability. These aren't vanity metrics. They tell you whether the foundation is stable enough to support analytics and AI.
A useful scorecard includes:
- Pipeline success and failure patterns. Don't just track whether jobs ran. Track where they fail, how often, and how long recovery takes.
- Data freshness by domain. Sales, finance, operations, and product rarely need identical latency targets. Measure freshness against business need.
- Data quality exceptions. Monitor schema changes, failed tests, null spikes, duplicate records, and business-rule violations.
- Query and workload performance. Watch cost-heavy queries, slow dashboards, and compute hotspots that create user frustration and waste budget.
- Change failure rate. If every release creates downstream incidents, your platform team is moving too fast or testing too little.
Tie platform metrics to business outcomes
Technical health matters because it supports business outcomes. You need to make that connection explicit.
Use a simple mapping model:
| Platform measure | Business implication |
|---|---|
| Fresher customer data | Faster response from sales, support, and retention teams |
| Trusted finance models | Quicker close cycles and fewer reconciliation disputes |
| Stable event pipelines | Better operational alerts and automation reliability |
| Reusable governed datasets | Faster launch of analytics and AI use cases |
| Lower manual data prep | More time for analysis, experimentation, and execution |
If your KPI deck only reports pipeline uptime, you're measuring infrastructure. If it links data quality and freshness to decision speed, you're measuring business performance.
Security is part of platform value
Security and governance aren't brakes on innovation. They're what make scale possible.
Centric Consulting's buyer-oriented guidance frames the outsourcing decision as a tradeoff between strategic leverage and dependency, with the key question being how to scale capabilities on demand while maintaining in-house governance and security. That's exactly right. You can outsource execution, but you shouldn't outsource accountability.
Your platform should enforce:
- Role-based access tied to business need
- Sensitive data controls such as masking, tokenization, and restricted datasets where appropriate
- Audit trails and lineage so teams know where data came from and who changed what
- Environment separation for development, testing, and production
- Clear access scopes approved with security and compliance stakeholders
For a concrete example of governance artifacts worth insisting on, review a model like the data access scope map handed to security teams. That kind of discipline keeps data platforms usable without turning them into unmanaged sprawl.
The Ultimate Vendor Evaluation Checklist
Most vendor evaluations are too shallow. Buyers ask about tools, certifications, and hourly rates. Vendors answer confidently. Nobody digs into operating model, ownership boundaries, or what happens six months after launch when data quality starts drifting and business logic changes.
That's how companies end up with a platform that looks polished in a demo and painful in production.

Questions that expose weak vendors fast
Don't ask generic questions like “Do you do data engineering?” Ask questions that reveal whether the vendor can build and operate a serious platform.
Use this checklist in meetings:
- Ask how they handle run-state operations. Who monitors pipelines? Who responds to failures? Who owns root-cause analysis? If they only talk about implementation, they're not solving your actual problem.
- Ask for their quality model. What tests do they write for ingestion, transformation, and business logic? How do they detect schema drift or silent data corruption?
- Ask how they support AI readiness. Can they structure governed datasets for ML, retrieval workflows, feature generation, or model monitoring inputs without creating shadow pipelines?
- Ask how they manage handoffs. Who is your delivery lead? Who makes architecture decisions? How often do you review risks, scope, and issue resolution?
- Ask what stays in-house. Strong vendors won't try to own your governance model. They'll define shared responsibility clearly.
- Ask how they prevent lock-in. Can your internal team understand and operate the delivered system if needed? Are documentation, tests, and lineage artifacts part of the delivery?
Weak vendors sell implementation. Strong vendors sell operating clarity.
What to inspect in the contract
The contract should tell you whether you're buying momentum or maintenance debt.
Xenoss highlights a critical gap in typical service evaluations: the true operating cost, including the recurring work required for observability, quality, monitoring, governance, and AI readiness over time. That's the issue most procurement processes miss.
Review these areas carefully:
- Scope language. Does it include observability, alerting, data quality, and post-launch support, or only build tasks?
- Acceptance criteria. Are deliverables defined by business-ready outcomes, or by technical activities completed?
- Documentation obligations. You need architecture diagrams, data contracts, runbooks, lineage notes, and ownership maps.
- Support model. Clarify incident response expectations, escalation paths, and change management routines.
- Commercial structure. Fixed-price can work for clearly bounded discovery or migration phases. Ongoing platform operation often fits a managed capacity model better.
- Exit terms. If the relationship changes, can your team take over without reverse-engineering the entire platform?
A good checklist doesn't just help you compare vendors. It changes the conversation. You stop buying technical labor and start buying accountable capability.
From Kickoff to ROI Sample Timelines and Case Studies
A lot of data engineering projects feel opaque because buyers only see two moments: the kickoff and the invoice. Good engagements are more structured than that. They move through a clear rhythm, produce visible artifacts, and create value in stages rather than in one dramatic launch.
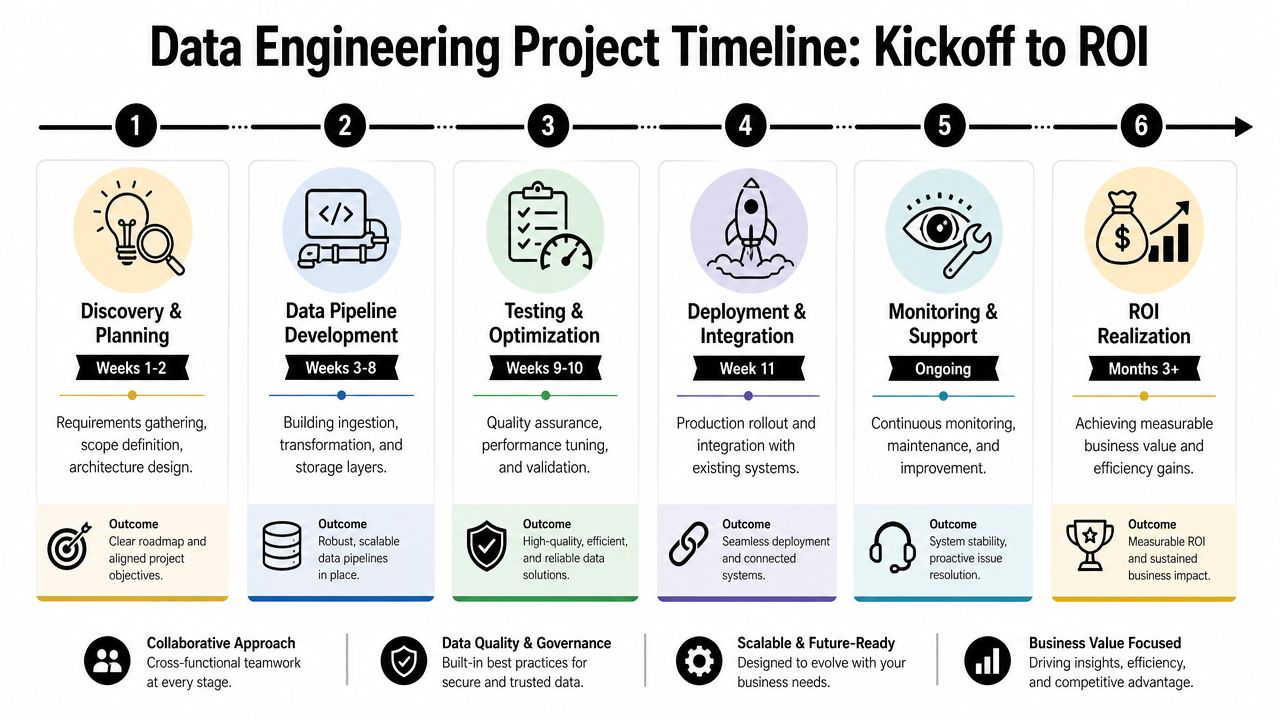
A realistic engagement rhythm
Most effective programs follow a pattern close to this:
- Discovery and planning
Teams align on use cases, source systems, security constraints, data ownership, and target architecture. Weak assumptions are removed early in this stage. - Core platform build
Engineers establish ingestion patterns, storage layers, orchestration, environments, access controls, and baseline observability. - Priority pipeline development
The first high-value domains get modeled. Common examples include customer, revenue, product usage, fulfillment, or support operations. - Validation and optimization
Teams harden tests, tune performance, validate business logic with stakeholders, and fix reliability gaps before broad rollout. - Deployment and integration
Data products connect to BI tools, internal applications, AI workflows, reverse ETL destinations, or operational alerting systems. - Managed run state
Monitoring, issue response, quality reviews, backlog refinement, and platform evolution continue as part of normal operations.
Three case-study patterns that show what good looks like
You don't need flashy case studies to know whether a model works. Look for repeatable business patterns.
Retail and commerce A retailer wants better campaign targeting and more consistent customer reporting. The blocker isn't modeling. It's fragmented customer and transaction data across ecommerce, ad platforms, loyalty systems, and support tools. Strong data engineering services unify identity logic, standardize customer events, and deliver trusted datasets for segmentation, attribution, and recommendation workflows.
Manufacturing and field operations An industrial company wants predictive maintenance and better operational visibility. Raw machine, maintenance, and inventory data exist, but they arrive in different formats and at different speeds. The right platform combines historical records with current event feeds, applies quality rules, and creates a stable layer for alerts, analytics, and maintenance planning.
SaaS and product-led growth A software company wants to launch customer-facing analytics or internal usage intelligence. Product events, billing, account hierarchies, and CRM data don't line up cleanly. A mature data platform models accounts, subscriptions, usage, and support interactions into shared entities, which gives product, sales, and customer success teams one reliable operating view.
The best proof of work is a delivery model that makes outcomes repeatable, not a slide full of vague wins.
That's the practical path from kickoff to ROI. Clear scoping. Strong architecture. Incremental delivery. Ongoing operation. If a provider can't describe that path in concrete terms, they probably can't execute it cleanly either.
If your AI strategy is stuck behind unreliable data, fragmented systems, or an overloaded internal team, Silicon Prime AI can help you turn data engineering into a hands-free operating capability. You set the strategy. We carry the weight across architecture, delivery, and managed execution so your team can focus on business outcomes instead of pipeline firefighting.
Comments